Agent-in-the-Loop Sales Autonomy: Multi-Agent Orchestration across Flows, Apex, and Data Cloud
Abstract
Enterprise sales has always been a coordination problem. Sellers,
solution architects, pricing analysts, and legal reviewers negotiate in a
narrow time window, each holding partial knowledge about customer intent,
product constraints, risk posture, and margin targets. Contemporary
large-language-model (LLM) agents promise to speed this process, but unguarded
autonomy in revenue workflows can violate policy, leak sensitive information,
or erode unit economics. This paper proposes an “agent-in-the-loop” paradigm for sales
autonomy on Salesforce that is neither naive automation nor conservative
scripting. It is a multi-agent architecture in which specialized AI agents act
as tool-using collaborators that plan, retrieve, and reason, while Salesforce
Flows, Apex services, and Data Cloud enforce invariants about identity,
consent, pricing guardrails, and lifecycle state. The design makes three
contributions. First, it formalizes the separation of concerns between LLM
agents and the platform, treating agents as planners and explainers rather than
as oracles for rules or prices. Second, it develops a coordination substrate
for multi-agent orchestration combining event-driven Flows, idempotent Apex
actions, and Data Cloud features so that sub-tasks such as lead triage,
opportunity progression, CPQ suggestion, and entitlement lookup can proceed
concurrently under explicit approvals. Third, it specifies a governance program
and economic objective for “risk-sensitive autonomy,” in which agents can
optimize cycle time and win probability only within constraints on tail loss,
policy violations, and auditability. The result is a practical blueprint for
deploying sales copilots that accelerate work without sacrificing trust,
compliance, or margin.
Keywords: Salesforce, Data Cloud, Apex, Flow, multi-agent systems, conversational AI, human-in-the-loop, orchestration, revenue operations, CPQ, evaluation, governance
1. Introduction
Autonomy in sales is often framed as a
binary: either the human account executive does the work, or a monolithic
assistant automates it. Both extremes fail in enterprise practice. Human-only
processes scale poorly and scatter institutional knowledge across email
threads; full automation invites brittle, opaque behavior that does not survive
legal scrutiny or quarterly margin reviews. A more durable framing is
“agent-in-the-loop” autonomy. In this model, LLM agents act as planners,
researchers, drafters, and coordinators, but the authoritative sources of truth
for product configuration, price policy, contractual terms, and identity live
in Salesforce and its adjacent services. Agents propose; Flows and Apex check
and execute; approvers authorize with tiered thresholds; Data Cloud curates and
guards the data used for retrieval and reasoning. The human remains in the
loop, not as a rubber stamp, but as an adjudicator whose feedback shapes agent
behavior and whose approvals trigger state transitions.
Figure 1: Sales Autonomy Outcomes Landscape.
This paper builds a system-level account of how to do that on Salesforce. It digs below user experience into orchestration, data interfaces, guardrails, and economic objectives. It argues that the essential design choice is to architect agents as tool-using collaborators whose actions are mediated by platform services. That choice unlocks parallelism and resilience multiple specialized agents can work simultaneously on a deal while constraining them to safe operations. The rest of the paper develops the implications of this choice for architecture, coordination patterns, data governance, risk, and evaluation.
2. Background and Definitions
Multi-agent systems research supplies
the conceptual scaffolding for coordinating autonomous entities with distinct
capabilities and partial information. Enterprise sales work naturally
decomposes into specialized roles qualification, discovery, configuration,
pricing, and legal that can be mirrored by software agents provided one also
specifies norms for communication, authority, and conflict resolution.
Language-model agents add two affordances to this picture. They can understand
and produce natural language, which is the dominant medium of sales work, and
they can control tools, which is the dominant medium of software integration.
Yet they also inherit well-documented limitations: hallucination under
uncertainty, vulnerability to prompt injection, and drift when underlying data
changes. Agent-in-the-loop autonomy treats these limitations not as incidental
bugs but as design constraints.
Within the Salesforce ecosystem, three primitives anchor orchestration. Flows are declarative state machines that respond to platform events, enforce branching logic, and trigger approvals. Apex exposes idempotent, parameterized actions that encapsulate enterprise logic for CPQ, entitlement checks, or account hierarchies. Data Cloud unifies data from Sales, Service, and external systems and surfaces identity, consent, and segmentation as first-class artifacts. Together, these elements act as the rule-of-law for agents: when an agent needs to mutate records, obtain a price band, or fetch a clause, it must do so by invoking a Flow or Apex action, which then applies access control, validation, and audit logging.
3. A Reference Architecture for Multi-Agent Orchestration on
Salesforce
A practical architecture separates
planning and execution. At the perimeter, a conversation manager receives a
seller’s request, extracts intent and context, and drafts a high-level plan.
The plan is expressed as a small program of tool calls and sub-tasks retrieve
last three statements of work for a given account; ask the configuration agent
for two feasible bundles; request a price band with explicit discount
thresholds; propose an email to the customer with a rationale and citations.
The manager delegates sub-tasks to specialized agents that run concurrently,
each with a constrained toolset. The configuration agent calls Apex endpoints
that front a constraint solver and the product model; the pricing agent calls a
margin service that computes approval thresholds given contract terms and cost
forecasts; the retrieval agent asks a RAG service that is mounted on Data Cloud
indexes, constrained by the active user’s permissions; the explainer agent
assembles a narrative with inline references to passage IDs and object
snapshots. A guardrail service polices all inputs and outputs, ensuring that no
agent fabricates numbers, violates discount floors, or discloses restricted
attributes.
Execution happens on the platform. When an agent proposes a state change creating a quote, updating a contact, submitting an approval it emits a tool invocation that a Flow or Apex action executes if and only if policy allows. All such invocations leave a durable trail of inputs, outputs, and approvals attached to the relevant record. Because the Flow runtime is event-driven, the architecture supports parallelism: an opportunity progression flow can advance in response to a validated discovery note at the same time a pricing flow computes a band and a knowledge flow harvests citations. The agent layer never bypasses this fabric; it is a client, not a privileged backchannel.
4. Roles of Specialized Agents and the Case for Plurality
Specialization pays off in reliability
and latency. A single, generalist agent controlling every tool tends toward
long prompts, brittle plans, and opaque failure modes. A small constellation of
specialist agents outperforms it because each agent can be tuned for a single
job with a minimal context. A qualification agent can prioritize enrichment,
territory rules, and intent extraction; it does not need CPQ knowledge. A
configuration agent can reason over features, options, and compatibility under
the discipline of a solver, returning only feasible bundles with minimal
explanations. A pricing agent can focus on computing and explaining a price
band that respects contract terms, list price, margin floors, and exception
policies. A retrieval agent can master the quirks of CRM content contracts,
emails, cases, knowledge and balance lexical and dense search against Data
Cloud indexes. An explainer agent can render the whole as a coherent narrative
with citations. Orchestrated correctly, these agents compose into a workflow
where the human remains in control while the machine does the heavy lifting.
Plurality also creates a natural unit for evaluation. Each agent can be tested offline with agent-specific metrics and guardrails, and the system can be evaluated end-to-end with business outcomes such as time to first proposal, approval escalations, and realized margin dispersion. Because the agents communicate through the platform’s public interfaces, one can upgrade a single agent without destabilizing the rest.
5. Orchestration Patterns across Flows, Apex, and Data Cloud
Figure 2: Event-Driven Concurrency via Platform Event Bus.
Coordination rests on a small set of patterns. The first is plan-and-validate. The conversation manager proposes a plan, but execution is staged through validation tools that check feasibility against the product model and policy intents before any state change occurs. The second is event-driven concurrency. Each agent submits tool requests that post events to the platform. Flows subscribe to these events and execute idempotent actions; retries are safe because actions carry idempotency keys. The third is compensating transactions. In sales it is common to adjust a quote after new information arrives. The architecture records a reversible diff for each agent-initiated change; a Flow can roll back or supersede changes atomically when an approver rejects or a policy changes. The fourth is progressive disclosure. Retrieval citations, configuration rationales, and price calculations are retained as attachments, and the explainer agent builds the seller-facing summary and the manager-facing audit with different levels of detail from the same artifacts. The fifth is identity and consent binding. Data Cloud is the locus for identity resolution and consent; every agent query carries the active user’s identity and the customer’s consent state. Flows enforce this contract by rejecting tool calls that do not specify both.
These patterns keep the lines clear. Agents coordinate at the level of plans and messages; Flows and Apex enforce invariants and schedule work; Data Cloud keeps data available and policy-constrained. The result is a system that behaves like a team with a competent coordinator, not a tangle of scripts.
6. Risk-Sensitive Objectives and Economic Discipline
Autonomy earns its keep only when it
protects economics while reducing latency. A sales copilot should not maximize
raw win probability if doing so requires unsustainable discounts. Nor should it
optimize expected margin while ignoring tail risk from volatile costs or
delivery penalties.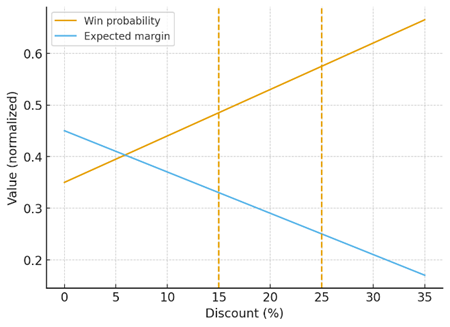
Figure 2: Discount vs Win Probability and Expected Margin.
A risk-sensitive objective balances these pressures. The pricing agent computes a feasible price band given list price, contract terms, and discount floors. It then estimates expected contribution margin and a tail-risk measure under demand and cost uncertainty. The explainer agent presents the trade-off succinctly: one point of additional discount is projected to raise win probability by a certain amount but risks breaching a margin guardrail or crossing an approval threshold that elongates cycle time. Approvers see the same calculation, not a rhetorical plea. This frame generalizes beyond price. The qualification agent can weigh enrichment cost and SLA against lift in downstream conversion; the retrieval agent can cap latency or compute-cost budgets per turn; the explainer agent can choose shorter narratives when the opportunity is close to forecast cutoff. The shared principle is to treat economic and risk metrics as first-class citizens of planning and to enforce guardrails by construction via platform policies.
7. Data Governance, Identity, and Consent
Sales autonomy lives or dies on
governance. Identity and consent are not peripheral; they are load-bearing
requirements. Data Cloud unifies customer profiles across systems, but the
architecture must also maintain a minimality principle. Agents retrieve and
process only what is necessary for the current task, and all tool calls include
a scope a specific account or opportunity, a time window, a data
classification. Retrieval is filtered by the active user’s permissions;
citations record object snapshots and file versions so that auditors can
reproduce the state under which an answer was produced. Personal data is masked
where possible before it enters the prompt, and channel-appropriate renderers
ensure that customer-facing content does not leak internal metrics or supplier
pricing. The human remains ultimately responsible for what leaves the
enterprise boundary, but the system is built to make the safe choice the path
of least resistance.
8. Safety, Security, and Robustness in Agent Communication
Language-model agents communicate in
natural language, which is both a strength and a liability. To prevent prompt
injection and untrusted content from hijacking an agent, the architecture never
treats natural language as executable intent. A plan must be expressed in a
restricted schema; a tool call must be schema-validated; and any action that
mutates state must be authorized by a Flow that re-checks policy. Outputs are
bounded by constrained decoding and post-filters that reject disallowed claims
about warranties, service levels, or prices. When agents pass messages, they
pass structured artifacts citations, IDs, parameterized requests alongside
summaries, so that downstream agents can verify rather than trust. The platform
acts as a firewall: untrusted inputs can influence the conversation but cannot
cause side effects without passing through the same approval gates a human
would face.
Resilience also demands time awareness. Sales data changes continually, and stale citations undermine trust. The retrieval agent computes and attaches freshness vectors to citations and refuses to answer with data outside policy freshness windows. Flows can revalidate drafts when upstream objects change, and approvers see staleness warnings in context. These mechanics convert “keep it fresh” from a slogan into an operational property.
9. Failure Modes and How the System Contains Them
In practice, failures cluster into four
categories. Retrieval failures occur when the needed clause or case note is
absent from the index or filtered out by permissions. The retrieval agent
detects low answerability and asks clarifying questions rather than
fabricating, while the platform exposes a “request index update” action that
signals ingestion gaps. Selection failures occur when candidates are broadly
relevant but none directly answer the question; the re-ranking step emphasizes
answer-bearing passages and the explainer is trained to cite exact spans.
Generation failures occur when the model composes incompatible claims or
misreads tables; the architecture mitigates them by preferring tool outputs for
numbers, enforcing citation-first decoding, and running structured validators
over drafts. Governance failures occur when outputs violate policy or leak
sensitive data; the platform’s guardrails and approval tiers catch these at the
point of effect, and post-hoc anomaly detection scans retrieval patterns to
flag suspicious cross-account access even when enforcement succeeds. The point
is not to eliminate failure but to confine it to zones where it can be detected
and reversed without harm.
10. Evaluation and Assurance
Evaluation must connect system-internal
metrics with business outcomes. Offline, each agent is tested against
agent-specific datasets. A configuration agent is measured by feasibility rate
and minimality of clarifying questions; a pricing agent by accuracy of
price-band computation under historical conditions and by calibration of
expected margin; a retrieval agent by recall and answerability over labeled
passage sets; an explainer by factual consistency with citations. Online, the
system is rolled out with canaries and control groups. The primary outcomes are
time to first proposal, approval escalation rate, win rate at fixed guardrails,
realized margin dispersion, and the incidence of reversals due to governance
violations. Guardrail health is tracked as its own set of metrics: denial rates
for unsafe tool calls, rate of redactions in customer-facing content, and
staleness in citations at the time of approval. The organization also adopts a
“glass-box” audit practice. Every significant agent action is recorded with
inputs, outputs, and approvals; auditors can reconstruct the chain of evidence
behind any quote or recommendation. This auditability is a design feature, not
an afterthought.
11. Case Narrative: An End-To-End Cycle under Agent-in-the-Loop
Autonomy
Consider a mid-market technology vendor
with a global sales team. A seller opens a net-new opportunity and types a
natural question into Salesforce: budget indication, desired deployment window,
and a few constraints about compliance and rack space. The conversation manager
identifies a plan: qualification, configuration, pricing, and draft
communication. The qualification agent enriches the account with firmographic
data, proposes a territory assignment, and asks one clarifying question about a
regional data-residency requirement. The configuration agent proposes two
feasible bundles and explains the trade-off between headroom and lead time. The
pricing agent computes a price band conditioned on the account’s contract,
current cost forecasts, and a risk-sensitive objective that keeps tail loss
within policy. The explainer agent composes an internal rationale and a
customer-facing draft email, each with citations to Data Cloud documents and
object snapshots. Flows execute the creation of a quote and submit an approval
request with computed thresholds. The manager approves automatically because
the draft sits inside the self-approval band; legal is not involved because
warranties match policy and no custom terms are invoked.
The customer counters with a steeper discount and a request for a longer warranty. The pricing agent recomputes, the configuration agent proposes a component swap that reduces cost volatility, and the explainer updates the draft with a transparent rationale. Because the tail-risk constraint would be breached, the Flow routes to finance for an exception. Finance sees the exact calculation and approves contingent on altering installation timing. The seller closes the loop with the customer using the explainer’s draft, and the opportunity progresses. Post-mortem analytics show shorter cycle time, fewer escalations, and tighter realized margin dispersion relative to the team’s historical performance.
12. Limitations and Future Directions
Agent-in-the-loop autonomy does not
abolish uncertainty. Language models remain susceptible to drift, and retrieval
over enterprise data is brittle in the presence of messy documents or ambiguous
questions. Demand and cost estimates are uncertain, and therefore
risk-sensitive pricing is only as good as its uncertainty models. The platform
itself can be a bottleneck if Flows are overloaded or if idempotency is not
carefully designed. Future work should explore learned routing among agents to
reduce latency; tighter late-interaction methods for re-ranking that approach
cross-encoder quality at lower cost; formal methods for verifying small but
critical policy invariants at the Flow level; and feedback-efficient ways to
incorporate manager adjudications into agent planning without destabilizing
behavior. It is also worth investigating market design for attention how to
orchestrate when several opportunities compete for the same set of specialist
agents and the economics of caching citation sets rather than generated text to
contain cost without sacrificing freshness.
Figure 4: Risk Heat Map Likelihood vs Impact.
13. Conclusion
Sales autonomy that earns trust is
neither a scripted wizard nor an unconstrained bot. It is a disciplined
collaboration among people, platform, and a small society of specialized
language-model agents. Treating the agents as planners and explainers, and
constraining their actions to policy-checked Flows and Apex services over Data
Cloud, resolves the tension between speed and safety. The architecture
described here demonstrates how to parallelize work, expose trade-offs
transparently, and keep humans in charge of the irreversible steps of the
revenue lifecycle. In doing so it turns autonomy from a demo into a dependable
capability: faster cycles, clearer rationales, fewer policy violations, and
margins that are protected by design rather than by luck.
14. References
- Y. Shoham, K. Leyton-Brown. Multiagent Systems: Algorithmic, Game-Theoretic, and Logical Foundations. Cambridge University Press, 2008.
- P. Hernandez-Leal, B. Kartal, M. E. Taylor. “A survey and critique of
multiagent deep reinforcement learning.” Autonomous Agents and Multi-Agent
Systems, 2019; 33: 750-797.
- R. S. Sutton, D. Precup, and S. Singh, “Between MDPs and semi-MDPs: A
framework for temporal abstraction in reinforcement learning.” Artificial
Intelligence, 1999; 112: 181-211.
- P. F. Christiano, J. Leike, T. Brown, et al., “Deep reinforcement
learning from human preferences.” 2017.
- L. Ouyang, J. Wu, X. Jiang, et al. “Training language models to follow
instructions with human feedback.” 2022.
- Y. Bai, A. Kadavath, A. Kundu, et al. “Constitutional AI: Harmlessness
from AI feedback.” 2022.
- P. Lewis, E. Perez, A. Piktus, et al. “Retrieval-Augmented Generation
for Knowledge-Intensive NLP.” 2020.
- O. Khattab, M. Zaharia. “ColBERT: Efficient and effective passage search
via contextualized late interaction over BERT.” In: Proc. SIGIR, 2020; 39-48.
- V. Karpukhin, B. Oguz, S. Min, et al. “Dense Passage Retrieval for
Open-Domain Question Answering.” In: Proc. EMNLP, 2020; 6769-6781.
- S. Yao, Y. Zhao, D. Yu, et al., “ReAct: Synergizing reasoning and acting
in language models.” 2022.
- T. Schick, J. Dwivedi-Yu, S. Sinha, et al. “Toolformer: Language models
can teach themselves to use tools.” 2023.
- N. Shinn, S. Labash, D. Gopinath. “Reflexion: An autonomous agent with
dynamic memory and self-reflection.” 2023.
- J. Wei, X. Wang, D. Schuurmans. “Chain-of-Thought prompting elicits
reasoning in large language models.” 2022.
- Y. Yao, D. Yu, J. Zhao. “Tree of Thoughts: Deliberate problem solving
with large language models.” 2023.
- C. Dwork. “Differential privacy.” In: Automata, Languages and
Programming, 2006; 1-12.
- R. T. Rockafellar, S. Uryasev. “Conditional value-at-risk for general
loss distributions.” Journal of Banking & Finance, 2002; 26: 1443-1471.
- A. Ben-Tal, L. El Ghaoui, A. Nemirovski. Robust Optimization. Princeton
University Press, 2009.
- R. L. Phillips, Pricing and Revenue Optimization. Cambridge University
Press, 2005.
- P. Liang, R. Bommasani, T. Lee. “Holistic evaluation of language
models.” 2022.
- M. T. Ribeiro, S. Singh, C. Guestrin. “Why should I trust you?:
Explaining the predictions of any classifier.” In: Proc. KDD, 2016; 1135-1144.