Data Engineering Mastery: Automation Essentials for Researchers and Students
Abstract
Automation has become a critical aspect of data engineering, revolutionizing the way data-driven projects are executed. Data engineering is a crucial discipline that focuses on the design and construction of systems and processes for collecting, storing and analyzing data. In the digital age, as the volume of data generated continues to grow exponentially, data engineers play an essential role in ensuring that data is accessible, dependable and usable for analytics and decision-making. For students and researchers, understanding the principles of data engineering is vital for leveraging data effectively in their projects and studies. This knowledge lays the groundwork for mastering the automation of data processes, which is increasingly becoming a standard practice in the industry. In this research paper, we explore the essential tools and techniques for automating data engineering tasks, with a focus on their practical applications for students and researchers. Data quality is also a paramount concern in data engineering. Ensuring that the data being processed is accurate, consistent and up to date is fundamental for any analysis or research. Automation can enhance data quality through the implementation of validation rules and monitoring systems that detect anomalies or inconsistencies in real time. By incorporating these automated quality checks into data pipelines, students and researchers can increase their confidence in the results of their analyses, ultimately leading to more reliable conclusions and insights.
The paper talks about the essentials of data engineering, the importance of automation in this field and the tools and techniques that can be used to automate data engineering tasks. The paper discusses the challenges associated with data quality and integration, tools selections and implementation, scalability and deployment. Paper also discusses about future trends in data engineering automation and its implications for students and researchers especially Impact of AI and Machine Learning.
Keywords: Databases, Noise Reduction, Outlier Detection, Data Normalization, Apache Kafka, AIML, Support Vector Machines (SVM), Delta live tables
1. Introduction
Data engineering has emerged as a critical discipline in the era of big data, as organizations and researchers alike grapple with the challenges of managing and extracting value from the vast amounts of data being generated.
In the digital age, data engineering has become a critical discipline, as the exponential growth in data generation necessitates robust systems and processes for collection, storage and analysis. Data engineers play a vital role in ensuring that data is accessible, dependable and usable for analytics and decision-making. For students and researchers, understanding the principles of data engineering is essential for effectively leveraging data in their projects and studies. This knowledge forms the foundation for mastering the automation of data processes, which is increasingly becoming a standard practice in the industry.
At the core of data engineering lies the concept of data pipelines - a series of data processing steps that involve the extraction, transformation and loading of data from various sources into a unified repository. Automation is critical in these processes, as it enables the seamless movement of data without the need for manual intervention. By automating data pipelines, students and researchers can save valuable time, reduce the risk of errors and focus on analyzing and interpreting the data rather than on the mechanics of data handling.
Another crucial aspect of data engineering is the selection and management of appropriate data storage solutions. With a wide range of options, including relational databases, NoSQL databases and cloud storage services, understanding the strengths and weaknesses of each is imperative. Students and researchers must evaluate their needs based on data size, structure and access requirements, as the choice of storage solution can significantly impact the performance and scalability of data operations.
Data quality is also a paramount concern in data engineering. Ensuring the accuracy, consistency and timeliness of the data being processed is fundamental for any analysis or research. Automation can enhance data quality through the implementation of validation rules and monitoring systems that detect anomalies or inconsistencies in real time. By incorporating these automated quality checks into data pipelines, students and researchers can increase their confidence in the results of their analyses, ultimately leading to more reliable conclusions and insights.
The increasing complexity and volume of data necessitate advanced methods for efficient data management and processing. Traditional data engineering processes often struggle to keep up with the demands of modern data-driven environments. Automation offers a solution by enabling seamless data collection, transformation and integration, ensuring high-quality data for analysis and decision-making. This paper examines the role of automation in data engineering, presenting a detailed methodology for implementing automated data workflows.
2. Methodology
One of the primary advantages of automation in data engineering is the increased efficiency it brings to data handling. Students and researchers often work with vast amounts of data that require cleaning, transformation and analysis. Automation tools such as ETL (Extract, Transform, Load) frameworks facilitate these processes, allowing users to set up workflows that can run independently. This not only saves time but also ensures that data is consistently processed in an accurate manner. Mastering these tools gives students and researchers a competitive edge, preparing them for the demands of the job market where data skills are increasingly sought after.
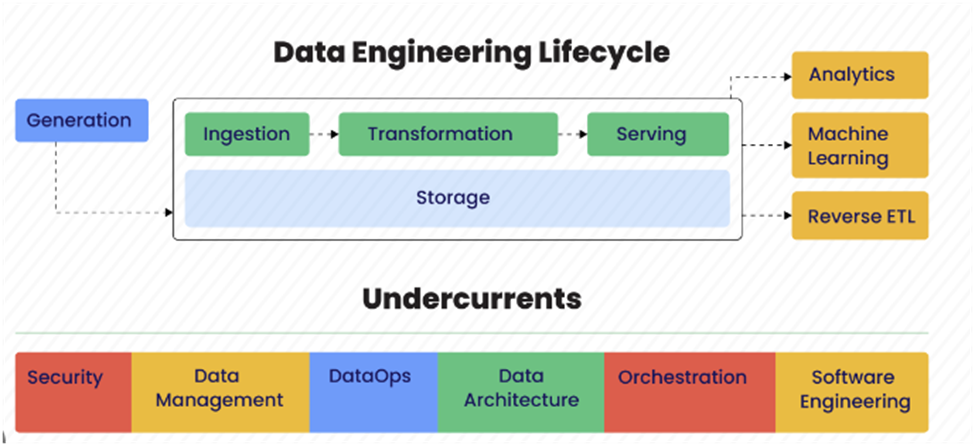
Figure1: Above flows show the data engineering life cycle.
This paper presents the essential steps for implementing an automated data engineering workflow:
2.1. Data Collection and Preprocessing
Here talks about different steps and processes required for (Endel & Piringer, 2015) collecting, validating and preprocessing data for analysis.
2.1.1. Data Sources: Data sources available in the digital world are continuously expanding, ranging from traditional databases to real-time streaming data. Following are the difference data sources.
A. Databases
SQL Databases: Relational databases like MySQL, PostgreSQL and SQL Server that use structured query language. Efficient setup involves connection pooling, while optimization includes indexing, query rewriting and execution plans. Managing large datasets may require partitioning, sharding and distributed databases.
NoSQL databases like MongoDB, Cassandra and Redis manage unstructured, high-velocity data. Efficient setup uses appropriate drivers and connection pooling, while optimization involves indexing and suitable data models.
Managing large datasets often requires horizontal scaling and replication.
B. Web Scraping
HTML Data Extraction: Use libraries like Beautiful Soup (Python) or Cheerio (JavaScript) to parse and extract data from HTML documents.
Dynamically Rendered Content: For content loaded via JavaScript after the initial HTML, use tools like Selenium or Puppeteer to interact with and capture this dynamic content.
Anti-Scraping Measures: Websites may use CAPTCHAs, IP blocking and rate limiting to prevent scraping. To manage these, you can rotate IP addresses, use headless browsers and respect robots.txt files to avoid detection.
C. Data from third party APIs
Following is the different way of collecting data from API.
Secure API Key Handling: This involves securely storing and managing API keys to authenticate requests. It often includes rotating keys and using environment variables to keep keys secure.
Rate Limiting: This is the process of controlling the number of requests a client can make to an API within a certain time to prevent abuse and ensure fair usage.
Parsing JSON/XML Responses: This involves converting the data received from APIs (usually in JSON or XML format) into a usable format within your application. Libraries and tools like Json in Python or Jackson in Java can be used for this purpose.
D. IoT Devices
Following are the sources for sensor data from IoT devices:
MQTT and HTTP Protocols: MQTT is a lightweight messaging protocol ideal for high-latency or unreliable networks, making it perfect for small sensors and mobile devices. In contrast, HTTP is a widely adopted protocol primarily used for web-based communication.
Streaming real-time data: This involves processing data as it is generated, often using frameworks like Apache Kafka or AWS Kinesis.
Processing Data at Scale: This requires efficient data ingestion, storage and processing mechanisms. Techniques include using time-series databases, edge computing and data compression.
2.1.2. Data Cleaning: After collecting the data from various sources, the next step is to clean the data. This involves the following techniques.
A. Noise Reduction
Statistical methods for noise reduction are essential for smoothing out random variations in data to reveal underlying patterns. Here are some commonly used techniques:
Moving Averages: Following are the different moving average techniques.
•Simple Moving Average (SMA): This method calculates the average of a fixed number of past data points. It is useful for smoothing time series data.
•Exponential Moving Average (EMA): This gives more weight to recent data points, making it more responsive to recent changes compared to SMA.
Gaussian Filters
This technique applies a Gaussian function to the data, which helps to reduce noise while preserving important signal characteristics. It is widely used in image processing and time series analysis.
•Wavelet Transform: This method decomposes data into different frequency components and then applies thresholding to remove noise. It is useful for both time series and image data.
Median Filtering
•This non-linear method replaces each data point with the median of neighboring data points. It is effective for removing outliers and preserving edges in image data.
•Outlier Detection Algorithms (e.g., DBSCAN): Density-Based Spatial Clustering of Applications with Noise (DBSCAN) identifies clusters in data and marks points that do not fit well into any cluster as noise.
B. Missing Data Handling
Managing missing data is crucial for maintaining the integrity and quality of datasets. Here are some common techniques used to address missing data:
Imputation Techniques: This involves filling in missing values with substituted values. Here are some popular methods:
•Mean/Median/Mode Imputation: Replace missing values with the mean, median or mode of the column. This is simple but can introduce bias if the data is not normally distributed.
•K-Nearest Neighbors (KNN) Imputation: This method fills in missing values by averaging the values of the k-nearest neighbors. It considers the similarity between data points, making it more accurate than mean imputation.
•Multiple Imputation by Chained Equations (MICE): MICE generate multiple imputations for missing data by creating several different plausible datasets and combining results. It uses a series of regression models to predict missing values.
•Model-Based Imputation: This involves using statistical models, such as linear regression or machine learning models, to predict and fill in missing values based on other available data.
Deletion Techniques: Deletion involves removing data points or features with missing values. This can be done in several ways:
•Listwise Deletion: Remove any data points (rows) that have missing values. This is straightforward but can result in significant data loss if many values are missing.
•Pairwise Deletion: Use all available data without discarding entire rows. This method uses different subsets of data for different analyses, which can be more efficient but may introduce inconsistencies.
Advanced Techniques: These are used when simple imputation or deletion is not sufficient:
•Expectation-Maximization (EM): This iterative method estimates missing values by finding the most likely values based on the observed data. It is useful for handling missing data in complex datasets.
•Hot Deck Imputation: This method replaces missing values with observed values from similar records. It is often used in survey data.
•Cold Deck Imputation: Similar to hot deck, but the replacement values come from an external source or a previous dataset.
Managing Missing Data in Time Series: Please see the specialized techniques:
•Forward Fill/Backward Fill: Fill missing values with the last observed value (forward fill) or the next observed value (backward fill). This is useful for time series data where continuity is important.
•Interpolation: Estimate missing values by interpolating between known values. Linear interpolation is common, but more complex methods like spline interpolation can also be used.
C. Outlier Detection
Outlier detection aims to identify and manage anomalies that can skew analysis.
Techniques include:
A box plot is a graphical representation that identifies outliers in a dataset. The key components of a box plot include the median, first quartile (Q1), third quartile (Q3), interquartile range (the range between Q1 and Q3) and whiskers extending to the smallest and largest non-outlier values. Outliers are data points that fall outside the whiskers.
Z-score analysis calculates the standard deviation of the data and flags any data points that deviate from the mean by more than a certain number of standard deviations (typically 3 or more) as outliers.
Isolation Forests: This machine learning algorithm isolates observations by randomly selecting a feature and then randomly selecting a split value between the maximum and minimum values of the selected feature.
Robust Statistical Methods: These include techniques like the Z-score, which measures how many standard deviations an element is from the mean and the Modified Z-score, which is more robust to outliers.
2.1.3. Data Normalization:
Data normalization means standardizing data formats and structures to ensure consistency across different sources:
Following are the tools and techniques for data normalization.
A. Schema Matching involves aligning data schemas from different sources to a common format. This ensures that data from various sources can be integrated and analyzed consistently. Tools and techniques include Apache Avro, Apache Parquet, Schema Mapping Tools. Automating the process of data normalization and schema alignment can greatly improve the efficiency and scalability of data engineering workflows.
B. Unit Standardization
This ensures that all measurements are converted to standard units, making data comparable across different sources. This is crucial for accurate analysis and reporting. Techniques and tools include:
Point Library: A Python library that manages physical quantities, allowing for easy conversion between different units. It supports arithmetic operations and unit conversions, ensuring consistency in measurements.
Manual Conversion: Involves writing custom scripts to convert units based on predefined conversion factors. This can be done using programming languages like Python, R or SQL.
C. Time Series Alignment
This involves synchronizing timestamps across datasets to ensure temporal consistency. This is essential for accurate time-based analysis. Tools and techniques include Python Pandas, Dask libraries and SQL date/time functions, Time Series Analysis Techniques like interpolation, resampling and rolling windows.
D. Tool Selection and Implementation
Paper talks about appropriate tools for automating data engineering process
ETL: Evaluating and Implementing ETL Tools to Automate Data Extraction, Transformation and Loading Processes: Effective data engineering requires the strategic selection and implementation of ETL tools to streamline and automate the critical tasks of extracting data from various sources, transforming it into a consistent format and loading it into a target data store or system. Key considerations in the evaluation and implementation of ETL tools include their capabilities, connectivity, scalability, ease of use and overall alignment with the organization's data management requirements and objectives.
Please see different tools use for ETL process in (Wickham, 2014) (Venkatakrishnan, 2020)
Apache NiFi: Provides a web-based UI for designing data flows, supports data provenance and ensures guaranteed delivery.
Talend: Offers a robust suite of tools for data integration, data quality and big data.
processing, with an extensive library of connectors.
Informatica: Known for its comprehensive data integration capabilities, data governance and robust data transformation functionalities.
Data integration platforms: These are tools or systems designed to combine data from different sources into a unified view. These platforms are essential for organizations that need to process and analyze large volumes of data in real-time. Following is common the tools use in data integration:
Apache Kafka: It can handle real-time data streams from multiple sources and deliver them to multiple consumers. It can add more nodes horizontally to manage increased load.
Amazon Glue: It is a serverless data integration service that makes it easy to discover, prepare and combine data for analytics, machine learning and application development.
Talend: Combines data integration, transformation and quality checks in one platform. Supports both Extract, Transform, Load (ETL) and Extract, Load, Transform (ELT) processes
iv. Informatica: Provides a variety of data integration and data management capabilities, including data quality, data security and master data management. Utilizes AI to automate and enhance data management processes.
Microsoft Azure Data Factory: cloud-based data integration service that enables the creation of data-driven workflows for orchestrating and automating data movement and transformation.
AWS Glue: A fully managed ETL service that automates the discovery, cataloging and transformation of data. It is a cloud-based solution
Google Cloud Dataflow: A unified stream and batch data processing service, offering autoscaling and flexible resource management. It is a cloud-based solution.
E. Automation Techniques
The paper also covers various automation techniques to streamline data engineering processes:
Scripting and Automation: Use of scripting languages like Python, Bash, PowerShell to automate repetitive tasks such as data extraction, transformation and load processes. These scripts can be integrated into workflow management tools for end-to-end automation.
Artificial intelligence and Machine Learning: Implementing machine learning algorithms for automated data quality monitoring, anomaly detection and predictive maintenance,
Data Quality Monitoring: Using supervised and unsupervised learning models to monitor data quality in real-time,
Data Assessment: Evaluate the characteristics of your data, such as volume, variety and velocity. Identify potential data quality issues like missing values, duplicates and inconsistencies. Use algorithms like Random Forests and Gradient Boosting to detect anomalies in data quality. These can help identify patterns that deviate from the norm.
Anomaly Detection: Deploying advanced ML models like Variational Autoencoders, Transformers, Autoregressive models, Diffusion models and Generative Adversarial Networks, have demonstrated remarkable capabilities in generating diverse and high-quality multimedia contents and networks to detect anomalies in data streams.
Predictive Maintenance: machine learning models to predict failures and schedule maintenance activities. Common algorithms include Time Series Analysis, Neural Networks and Support Vector Machines (SVM) .Deploy predictive models in a way that they can continuously learn and adapt to new data, ensuring ongoing accuracy and reliability.

Figure 2: Above shows different steps of AIML in data engineering.
Workflow Orchestration: Tools like Apache Airflow, Luigi, Dagster allow you to define data pipelines as directed acyclic graphs, making it easier to manage dependencies, schedule tasks and monitor the overall workflow
Containerization and Orchestration: Containerization tools like Docker and Kubernetes enable the packaging of data engineering applications and their dependencies into portable, reproducible containers. This facilitates automated deployment, scaling and management of data pipelines.
Incremental Data Processing: Techniques like Incremental Load, Delta Extraction and Change Data Capture help optimize data pipelines by only processing new or modified data, reducing computation and storage requirements.
By leveraging these automation techniques, data engineering teams can significantly improve the efficiency, reliability and scalability of their data processing workflows.
3. Results
The integration of automation tools and techniques in data engineering significantly enhances data collection, processing and analysis capabilities. Here the paper collects some of the details from different domains and organizations followed the above-mentioned method lines for improving productivity in data engineering.
Case study1: A leading insurance organization ask was to bring effective test data creation/migration techniques to reduce manual effort and ensure consistent data quality data migration and generation process. Challenges were managing the large volume of data generated from multiple interfaces. Organization automated by modernizing s for migrating and converting data and its format from production to lower environments by using below given platforms and techniques.
ETL Tool Selection: Implemented Apache NiFi for designing and managing data flows.
Data Integration: Used Apache Kafka to integrate data from various interfaces in realtime.
Data Quality Monitoring: Deployed machine learning algorithms Neural Networks and Support Vector Machines (SVM) to monitor data quality and detect anomalies.
It reduced manual intervention in ETL processes, leading to significant efficiency gains and enhanced data quality and consistency, enabling better decision making.
4. Model Implementation details
Please implementation details for data quality monitoring using algorithms Neural Networks, and Support Vector Machines (SVM)



Figure 3: Above script used for developing the model algorithms Neural Networks and Support Vector Machines (SVM), that is used for Detect Anomalies , Monitor and Report .Please see the steps involved
Steps
i Load Data: Load historical data for training and production data for monitoring.
ii Preprocess Data: Manage missing values and normalize the data using Standard Scaler.
iii Train Models: Train a Random Forest model and an SVM model on the historical data.
iv Detect Anomalies: Use the trained models to detect anomalies in the production data.
v Monitor and Report: Periodically monitor the production data transfer and report any detected anomalies.
Notes:
i Random Forest: Trained with the assumption that historical data has no anomalies (labelled as 0).
ii SVM: One-class SVM is used for anomaly detection.
iii Logging: Logs are used to report detected anomalies.
iv Periodic Monitoring: The script includes an example of how to periodically monitor the data transfer (e.g., every hour).

Figure 4: This flow shows process flow diagram from data ingestion to AI models.
Case study 2: A large e-commerce company applied machine learning models for real-time anomaly detection in inventory and sales data, allowing them to quickly identify and address issues.
Specifically, they utilized deep learning techniques like Variational Autoencoders and Transformers to model normal patterns in their data streams. Any deviations from these learned patterns were flagged as potential anomalies, enabling the company to proactively address issues before they impacted business operations.: Delta live tables for incremental processing to minimize compute and storage requirements. Set up Delta Live Tables to enable incremental processing, only ingesting new or changed data to reduce compute and storage overhead. Automated the deployment of data pipelines using containerization with Docker and orchestration with Kubernetes.
The adoption of these automation techniques resulted in faster data pipeline deployment and scalability.
5. Implementation details
The paper explains the implementation details of delta live tables for quality check that implemented as part of solutioning.
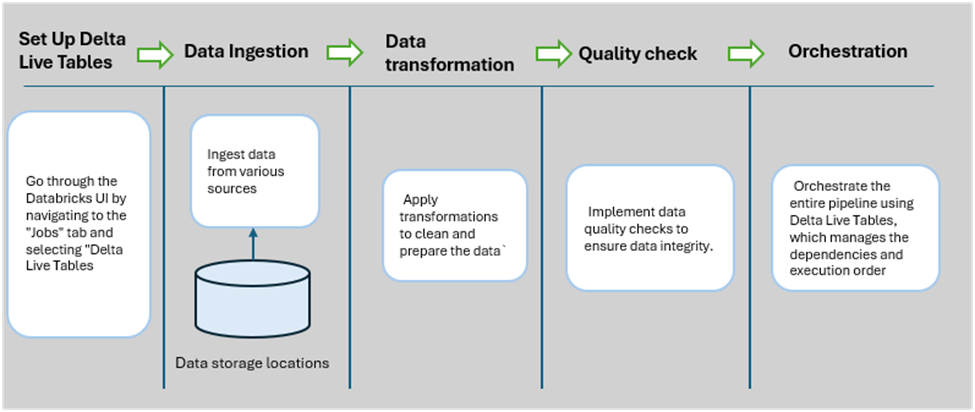
Fig 5: Process diagram from delta live tables to pipeline orchestration.


Python program used for data injection, transformation, quality check and orchestration for delta live tables.
By applying these techniques, the company was able to reduce manual effort in monitoring data health, while also improving forecast accuracy and inventory management
In conclusion, the adoption of data engineering automation tools and techniques has proven to be transformational for organizations across various domains. These solutions have enabled data teams to enhance efficiency, improve data quality and drive more informed decision-making.
6. Discussion
Here paper discusses challenges while implementing automation tools for data engineering and some of the thoughts for designing and testing automation process.
7. Challenges
The implementation of automation in data engineering presents several challenges that must be carefully addressed to ensure successful deployment and operation. This paper discusses the common obstacles encountered in the process, elaborating on the technical intricacies and implications of each challenge.
7.1. Data Quality and Integration:
Ensuring high-quality data and integrating data from various sources can be challenging. The data required for training AI and ML models comes from diverse sources, such as databases, APIs and IoT devices, leading to issues with data consistency, completeness and accuracy. Data heterogeneity complicates the integration process, as it requires a thorough understanding and mapping of different data models. Data may contain inconsistencies, duplicates, missing values and noise. These quality issues must be addressed through sophisticated data cleaning techniques, including anomaly detection, deduplication algorithms and imputation methods for missing data. Tracking the origin and transformations of data is crucial for ensuring data quality and compliance with regulations like GDPR. Implementing mechanisms to capture and manage metadata for data lineage is a complex task
7.2. Tool Selection and Implementation:
Selecting and implementing the appropriate tools for automating data engineering processes can be challenging. With a wide range of ETL tools, data integration platforms and cloud-based solutions available, it is crucial to choose the right tools that align with the organization's specific business needs and technical requirements. A thorough evaluation of available tools is necessary, considering factors such as scalability, ease of integration, performance, support for real-time processing and cost. Ensuring that the selected tools can seamlessly integrate with the existing data infrastructure is crucial. This involves configuring APIs, connectors and middleware solutions to facilitate smooth data flow and integration. Relying on proprietary solutions may lead to vendor lock-in, restricting future flexibility and scalability.
7.3. Scalability and Deployment
As data volumes and complexity grow, data engineering pipelines must be designed for efficient scalability. Automation tools and platforms must support both horizontal and vertical scalability. Distributed computing frameworks like Apache Spark and Hadoop enable horizontal scalability, while vertical scalability requires powerful, optimized hardware. Effective load balancing is crucial to distribute workloads evenly across processing nodes, preventing bottlenecks and ensuring optimal performance. Tools like Kubernetes offer sophisticated orchestration and load balancing capabilities for containerized applications. Implementing CI/CD pipelines for data engineering workflows ensures that changes are automatically evaluated, validated and deployed across environments. Tools like Jenkins, GitLab CI and AWS Code Pipeline facilitate the automation of these processes, enabling smoother and faster deployments. Maintaining observability over large-scale data environments requires robust monitoring tools that provide real-time insights into system health, performance metrics and anomaly detection. Solutions like Prometheus, Grafana and the ELK stack are commonly used to achieve comprehensive monitoring and observability.
8. Designing for Automation
Designing for automation in data engineering is a critical aspect that can significantly enhance the efficiency and effectiveness of data workflows. As students and researchers delve into this domain, it is essential to understand how to create systems that not only automate repetitive tasks but also maintain accuracy and scalability. This involves selecting the right tools and techniques that align with the specific requirements of the project, ensuring that the automated processes can integrate seamlessly with existing data pipelines. A well-thought-out design can facilitate quick iterations and adaptations as new data sources or requirements emerge.
Another critical consideration in automation design is the establishment of clear data governance policies. As automation can lead to the handling of vast amounts of data, ensuring data quality and compliance with relevant regulations is paramount. Students and researchers must incorporate data validation and monitoring processes into their automated workflows.
9. Testing Automation Processes
Implementing robust testing automation is a critical aspect of ensuring the reliability and efficiency of automated data engineering workflows. As students and researchers delve into the complexities of data engineering, understanding the principles and practices of testing automation is essential. This process not only identifies bugs and errors in the automation scripts but also validates that the automated workflows perform as expected under various conditions. By implementing rigorous testing automation, practitioners can enhance the overall quality of their data engineering pipelines, leading to more dependable results.
The choice of tools for testing automation significantly influences the effectiveness of the process. There are a variety of frameworks and libraries available that cater specifically to data engineering needs. Popular tools include Apache Airflow for workflow management, which allows for testing DAGs through unit tests and pytest for executing Python-based test cases. Students and researchers should familiarize themselves with these tools, as they facilitate the integration of testing into the development lifecycle, promoting a culture of continuous improvement.
10. Future Trends in Data Engineering Automation
Paper discusses feature trends on automation in data engineering that will help students and researchers for further enhancement.
11. Emerging Technologies
Emerging technologies are reshaping the landscape of data engineering, offering new tools and techniques that enhance automation processes. As students and researchers delve into this evolving field, understanding these innovations is crucial for staying ahead. Technologies such as artificial intelligence (AI), machine learning (ML) and big data analytics play pivotal roles in automating data workflows, enabling more efficient data handling and analysis.
One of the key emerging technologies in data engineering is AI-driven automation. AI algorithms can analyze vast datasets to identify patterns and insights that would be difficult for humans to discern. This capability allows for the automation of data preprocessing tasks, such as data cleaning and transformation.
Machine learning also plays a significant role in emerging automation technologies. With machine learning models, data engineers can automate predictive analytics, which is essential for making informed decisions based on historical data. These models can be trained to recognize trends and anomalies, enabling initiative-taking measures to be implemented before issues arise. The ability to predict future outcomes based on data patterns opens new avenues for research and application in various domains.
Another notable advancement is the integration of cloud computing with data engineering automation. Cloud platforms offer scalable resources and services that facilitate the storage, processing and analysis of large datasets. Technologies such as serverless computing allow data engineers to run automated tasks without managing physical servers, leading to cost efficiency and flexibility. The cloud also fosters collaboration, allowing teams to work together seamlessly regardless of geographical barriers.
Lastly, the rise of data orchestration tools represents a significant shift in how data workflows are managed. These tools automate the coordination of data movement across various systems, ensuring that data is collected, processed and delivered to end-users efficiently. With the growing complexity of data environments orchestration tools simplify the management of data pipelines, reducing the risk of errors and enhancing data integrity.
12. The Impact of AI and Machine Learning
The integration of artificial intelligence (AI) and machine learning (ML) into data engineering has revolutionized the way data is processed, analyzed and utilized. For students and researchers in this field, understanding the impact of these technologies is crucial. AI and ML algorithms enable automation of complex data workflows, significantly reducing the time and effort required for data preparation and analysis. This automation enhances efficiency and allows data engineers to focus on more strategic tasks, such as data architecture design and model development, ultimately leading to more innovative solutions.
Moreover, AI and ML facilitate advanced predictive analytics, which can transform how organizations make decisions based on data. By employing algorithms that learn from historical data patterns, data engineers can build models that predict future trends or outcomes. This predictive capability is essential in various applications, from financial forecasting to healthcare diagnostics. Understanding how to leverage these models is vital for students and researchers aiming to contribute to data-driven decision-making processes in their respective fields.
The use of AI and ML also fosters enhanced data quality and governance. Automated data cleansing and validation processes powered by machine learning algorithms can identify anomalies and inconsistencies in datasets that might go unnoticed in manual processes.
Finally, the ethical implications of AI and ML in data engineering cannot be overlooked. As these technologies become more embedded in data workflows, issues such as bias, privacy and accountability emerge as critical considerations. Students and researchers must engage with these ethical challenges, understanding the potential risks and responsibilities associated with deploying AI and ML solutions. This awareness not only enhances their technical proficiency but also prepares them to contribute to the development of ethical guidelines and best practices in the rapidly evolving landscape of data engineering.
13. Conclusion
The integration of automation in data engineering represents a transformative approach to enhancing data workflows and ensuring high-quality data processing. By leveraging advanced ETL tools, data integration platforms and machine learning algorithms organizations can achieve significant improvements in data collection, processing and analysis. This research provides a comprehensive guide for implementing automated data engineering solutions, highlighting key methodologies, challenges and strategies. The integration of modern technologies and best practices ensures that organizations can achieve robust and adaptive data engineering processes in dynamic data environments.
Ensuring robust data quality and security is paramount when automating data processes and this book addresses these critical concerns comprehensively. Implementing automated data validation checks and monitoring systems guarantees that incoming data meets the required standards before being processed. Furthermore, automation can bolster security measures by automatically enforcing data access policies and auditing changes in data. For students and researchers, prioritizing data quality and security in their automation practices will lead to more reliable results and foster greater trust in their methodologies.
Integrating machine learning into automation processes represents the future of data engineering. The book outlines how algorithms can be automated to enhance data analysis and decision making. This integration enables predictive analytics and real-time insights, which are invaluable for research and academic projects. Students and researchers should explore how machine learning can complement their automation efforts, allowing them to derive deeper insights from their data and push the boundaries of what is achievable in their respective fields. Embracing the constructive collaboration between automation and machine learning will prepare them for the evolving landscape of data engineering.
14. References
- https://arxiv.org/abs/1910.14436
- https://ieeexplore.ieee.org/document/4163027
- https://ieeexplore.ieee.org/document/7184914
- https://arxiv.org/abs/2210.14826
- https://ieeexplore.ieee.org/document/1191387
- https://iopscience.iop.org/article/10.1088/1757-899X/986/1/012015
- https://www.sciencedirect.com/science/article/abs/pii/016412129190050G?via%3Dihub
- https://hal.science/hal-00355368
- https://arxiv.org/pdf/2105.05699.pdf
- https://arxiv.org/abs/2001.07522
- https://link.springer.com/article/10.1007/s00778-015-0395-0
- https://www.sciencedirect.com/science/article/pii/S0888754312000626?via%3Dihub
- https://www.sciencedirect.com/science/article/pii/S2405896315001986?via%3Dihub
- https://ieeexplore.ieee.org/document/9151758
- https://link.springer.com/article/10.1007/s42979-023-01828-8
- https://www.sciencedirect.com/science/article/abs/pii/S0020025512006822?via%3Dihub
- Foidl H, Golendukhina V, Ramler R, Felderer M. Data
Pipeline Quality: Influencing Factors, Root Causes of Data-related Issues and
Processing Problem Areas for Developers. Cornell University 2023.
- Geurts P, Ernst D, Wehenkel
L. Extremely randomized trees. Springer Science+Business Media 2006;63(1):3-42.
- https://www.sciencedirect.com/science/article/pii/B9780124095472148796
- https://fmch.bmj.com/content/7/2/e000067
- https://www.mdpi.com/2227-7080/7/3/65
- https://onepetro.org/SPEATCE/proceedings-abstract/20ATCE/3-20ATCE/D031S035R006/449909
- https://ieeexplore.ieee.org/document/7004205
- https://ieeexplore.ieee.org/document/6107931
- Koc O, Uğur Ö, Selçuk-Kestel AS. The Impact of
Feature Selection and Transformation on Machine Learning Methods in Determining
Credit Scoring. Cornell University 2023.
- https://iopscience.iop.org/article/10.1088/1757-899X/263/4/042087
- Liu X. Optimizing ETL
Dataflow Using Shared Caching and Parallelization Methods. Cornell University
2014.
- https://www.jbc.org/article/S0021-9258(19)52451-6/pdf
- https://arxiv.org/abs/2203.10836
- Meng X, Wang D, Wu M, Wang P, Zhou Y Fu. Beyond
Discrete Selection: Continuous Embedding Space Optimization for Generative
Feature Selection. Cornell University 2023;(1).
- https://www.sciencedirect.com/science/article/abs/pii/S0065245814000114?via%3Dihub
- https://www.inderscience.com/offers.php?id=26274
- https://dl.acm.org/doi/10.1145/3379177.3388909
- https://arxiv.org/abs/2101.12127
- https://dl.acm.org/doi/10.1145/2771783.2771792
- https://journalofbigdata.springeropen.com/articles/10.1186/s40537-022-00673-5
- https://www.mdpi.com/1999-5903/3/4/281
- Perrone JB, Priest MA, Ali FT. Data
Management Acceleration Project: A Case Study In Doing It Right 2009.
- Polyzotis N, Zaharia M. What can Data-Centric AI
Learn from Data and ML Engineering? Cornell University 2021.
- https://arxiv.org/abs/2112.06439
- Rao KK, Rao M, Kavitha C,
Kumari GL, Surekha Y. Prioritization of Test Cases in Software Testing Using M
2 H 2 Optimization 2022;14(5):56-67.
- https://iopscience.iop.org/article/10.1088/1757-899X/1022/1/012014
- https://arxiv.org/abs/2102.11447
- https://www.tandfonline.com/doi/abs/10.1080/757583650
- https://arxiv.org/abs/2102.07750
- https://stats.oarc.ucla.edu/r/dae/robust-regression/
- https://iopscience.iop.org/article/10.1088/1742-6596/1694/1/012032
- https://analyticalsciencejournals.onlinelibrary.wiley.com/doi/10.1002/cem.1180050103
- https://wires.onlinelibrary.wiley.com/doi/10.1002/widm.1236
- https://ieeexplore.ieee.org/document/4351459
- https://arxiv.org/abs/2212.07517
- https://ieeexplore.ieee.org/document/9117435
- https://www.tandfonline.com/doi/full/10.1080/17434440.2017.1300057
- https://ieeexplore.ieee.org/document/9242800
- https://dl.acm.org/doi/10.1145/1107499.1107504
- http://ambysoft.com/downloads/TDDD.pdf
- http://vldb.org/pvldb/vol14/p2945-klimovic.pdf
- https://www.sciencedirect.com/science/article/pii/S1877705814023509?via%3Dihub
- https://ieeexplore.ieee.org/document/9223235
- Tomita TM, Browne JD, Shen C,
Chung J, Patsolic J, Falk B, Priebe CE, Yim J, Burns R, Maggioni M, Vogelstein
JT. Sparse
Projection Oblique Randomer Forests. Cornell University 2015.
- https://arxiv.org/abs/2306.02421
- https://aircconline.com/ijdms/V12N3/12320ijdms01.pdf
- https://onepetro.org/SPEIE/proceedings-abstract/10IE/All-10IE/SPE-127915-MS/106776
- https://ieeexplore.ieee.org/document/6784604
- https://arxiv.org/abs/2101.03970
- https://www.jstatsoft.org/article/view/v059i10
- https://arxiv.org/abs/2103.16007
- https://arxiv.org/abs/2303.04073
- https://link.springer.com/article/10.1007/s11432-018-9834-8