Enhancing Credit Risk Analysis in Financial CRMs using Retrieval-Augmented Generation and Predictive AI
Abstract
Credit risk evaluation has always been a
crucial part of the decision-making process in finance. However, researchers
face significant challenges trying to apply statistical models that are not
very malleable when it comes to reflecting the ever-changing behavior among
borrowers or the changes in the economic environment. A recent development in
machine learning, which can be categorized under Artificial Intelligence, is
the Retrieval-Augmented Generation (RAG). This paper proposes integrating RAG
with predictive AI models in credit risk analysis for financial CRM systems.
Thus, RAG systems enhance structured financial datasets since the derived
variables are real-time, borrower-specific and macroeconomic, enhancing the
accuracy and responsiveness of financial dataset predictions. Therefore, as
shown from the evaluations of the ChinaZJB SME dataset as well as other UCI
benchmark datasets, the integration of RAG improves the roots of traditional
prediction models, including Random Forest, Neural Networks, Support Vector
Machines and Logistic Regression in terms of accuracy, recall and AUC-ROC.
Further, the timely incorporation of new datasets reduces class imbalance and
enhances minor class prediction beyond 20%. It describes the system, which
includes the main elements, methods of data preparation, methods of training,
methods of building and selecting the model and data privacy issues. These
studies establish that integrating retrieval systems with AI shifts the
landscape of financial CRM technology to the next level of solutions that can
provide better customer experiences and agile and robust credit risk predictions.
The future development can be the progress in developing an efficient and
optimized retrieval system, integrating risk modelling for personal clients and
using the system in other financial decision-making.
Keywords:
Credit Risk Analysis, Retrieval-Augmented
Generation (RAG), Predictive AI, Financial CRM Systems, Machine Learning, Risk
Modeling.
1.
Introduction
Credit risk management has become a key
strategy that applies to the lending process to help manage and minimise the
probability of default on a loan to maintain financial stability. Consequently,
conventional risk measurement techniques primarily skewed toward historical
records and other financial ratios are inadequate in an unstable and globalized
world economy. With increasing competition, financial institutions are now more
focused on evaluating credit risk and for this purpose more effective and efficient,
accurate and interpretable models are also required1-3. Using dispensation, client data storage and
management, Fruit has developed from simple data storage and client database
retainers into comprehensive customer-contact response, portfolio monitoring
and decision-support tools. However, advanced credit risk analysis in CRMs has
been limited, especially due to inadequate scoring models and inflexible data
processing mechanisms. In order to tackle this deficit, there is a significant
potential for amending the existing financial CRMs by implementing innovative,
adaptive risk evaluation mechanisms that utilize voluminous real-time data
environments.
Retrieval-augmented generation (RAG) can
be considered the artificial intelligence breakthrough that incorporates large
language models with an information retrieval mechanism. By integrating such
data from outside the model, RAG offers a more up-to-date and broader base for
credit risk assessment. With the right AI models for borrower behavior,
macroeconomic signals and portfolio characteristics integrated to Risk risk-adjusted
growth, the effectiveness and dynamism of risk management in a financial CRM can
be elevated by RAG. This work unveils a new approach to combining
Retrieval-Augmented Generation and predictive methods into financial CRM
systems for intelligent credit risk analysis. The proposed architecture
simultaneously boosts the prediction performance, increases the
interpretability of the results and optimizes the computations. This paper
outlines the key aspects of the system design, such as data source
identification, data retrieval approach, model incorporation and system
efficiency assessment. Concerning research findings attained from real-world
financial datasets, the presented approach can outcompete previous risk models,
permitting financial organizations to yield more accurate, quicker and more
reliable credit decisions within a rising-native financial world.
2.
Related Work
2.1. Traditional credit risk models
Traditional credit risk models have been organizations’
primary framework in evaluating default risk, loss frequencies and regulatory
capital charges. Models like Credit Metrics™ used by J.P. Morgan or Credit Risk
+™ of Credit Suisse companies follow the default mode or the mark-to-market
approach to determine the behavior of credit portfolios. Such systems primarily
refer to historical data for borrowers, internal credit scores and non-changing
financial ratios for risk measurement. A characteristic that most of these model’s
share is that they are unconscious models of credit risk where comparisons
between borrowers’ characteristics and their defaults are relatively static or
invariant to credit cycles4-7. However,
it becomes ineffective, especially in complex or changing economic scenarios of
the Italian economy, which are dynamic. They cannot take and respond to
real-time cues that the economy provides, for instance, changes in interest
rates, geopolitical risk or a particular sector’s decline. Reliance on past
information limits them in evaluating non-conventional borrowers or fresh
financial risks. Especially in economic distress, these constraints will result
in under or overestimating risks, portfolio vulnerability and regulatory compliance.
2.2. Use of AI and machine learning in
risk assessment
AI and ML have revolutionized credit risk
analysis by improving ways to inspect data and find unknown relations within
big data space. Tools like Random Forest, Support Vector Machines (SVMs) and
different types of Neural Networks also help risk analysts to integrate all
sorts of structured & unstructured hard & soft data records like
Transaction history, Geo mapping data and Behavioral Patterns from Social media
posts. Random Forests are much more likely to detect more complex borrower risk
factors than a single decision tree. Deep Neural Networks are very proficient in
modelling complex variable interactions. However, the implementation of these
models has been subject to criticism due to the interpretability of the models.
AI algorithms operate based on unexplained models, making it challenging for
financial institutions to explain credit decisions to regulators and auditors.
To this end, methods such as Shapley values and LIME (Local Interpretable
Model-Agnostic Explanations) have been created to provide much more
interpretability without much reduction in accuracy. Nevertheless, critics of
Artificial Intelligence have raised issues of data privacy, bias and fairness
in the model; however, they have proven their competence in bringing down
default rates, improving credit scoring and credit risk assessment, as well as
extending credit accessibility to under-banked and unbanked populations hence
revolutionizing the risk assessment market.
2.3. Retrieval-augmented generation (RAG)
in financial applications
Retrieval-augmented generation (RAG) is a
crucial development, particularly FOR artificial intelligence applications
entailing action-based creativity, which dynamically correlates with existing
information. RAG architectures enable models to retrieve the latest information
from databases and/or the web to provide accurate and timely information in
responses to queries processed. The large language models (LLMs) introduced
into the RAG architectures provide an ability to bring external data for the
current and accurate output. In a credit risk analysis, RAG allows an organization’s
CRM systems to integrate up-to-the-minute financial conditions, changes in
regulations and borrower information into its risk assessment processes. For
instance, when using a RAG-enhanced CRM, the ability to obtain up-to-date
macroeconomic factors such as unemployment rates, inflation rates or policy
shifts together with borrower-specific changes such as revised income or
spending are used to fine-tune the risk measurements even further. This
addresses the knowledge cutoff major drawback that has been realized in most AI
models and also ensures that there are minimal hallucinations because the
answer is obtained from an authoritative source. Automated compliance
reporting, anti-money laundering (AML) screening and personalized investment
advisory are also some of the applications many financial institutions use RAG
for, apart from credit scoring. Since RAG offers tangible and transparent
results supported by proof, the system is a pioneering tool in the
metamorphosis of smart, compliance-conscious and adaptive financial CRM
solutions.
3.
Proposed Methodology
3.1. System architecture overview
The architecture of the proposed approach
that enriches credit risk analysis in financial CRM systems comprises real-time
data ingestion, Retrieval-Augmented Generation (RAG) for dynamic contextual
retrieval and advanced Predictive AI models for risk classification. The
overall system is presented in Figure 1 below and is designed to prevent such
drawbacks of a static model by regularly incorporating external financial
indicators and customer behavior signals into the risk assessment8-12. This can be achieved by designing the
application modularly, where data flows from external sources, through
individual CRM system components, into RAGs and then to the predictive analytic
engines. At the base, the system takes multiple raw, non-structured inputs in
financial transactions, raw credit bureau feeds, communication records and
other external signals, such as market updates or fraud trends. Over time, it
is kept in the CRM Data Warehouse with in-house information such as customer
database risk evaluation. The results of each query are query embeddings that
express a certain risk profile of the customer, which allows for information
search and retrieval by the RAG module within a particular context.
The Retrieval-Augmented Generation (RAG)
is designed to act as the final link between static CRM data and real external
knowledge. As an information search technology, it processes analyst queries,
searches for relevant documents and provides rich contextual data. This output
is then entered into the Predictive AI Risk Analysis engine, which means that
credit risk scores are not only based on static attributes of a borrower but,
in addition to that, are supplied with real financial and behavioral data. For feature
engineering, risk scoring and feature explanation, the predictive engine uses a
combination of XG Boost, deep neural nets (DNN) and decision trees. In order to
ensure that the assembling remains stable and the model remains relevant to the
selected system, there is the Model Management and Feedback Loop responsible
for evaluating the performance and checking for model shifts. Whenever there is
a change in dataset characteristics or model performance, the regulation of
retraining processes, update of the deployed models and registration happens
systematically. Records are updated constantly in an interactive CRM dashboard,
which enables the risk taker to either ratify or dispute the risk scores
assigned by the application, thus eliminating the human-in-the-loop dilemma.
Last, the User Interaction and Monitoring
module includes the real-time risk profile visualization, the risk score
rationale and the heat-map interface. The analysts can look at specific
customer data tables with selected fields, work with new risk alerts to follow
and provide feedback that improves the algorithms used in the models (Figure
1). This synergy makes it possible to improve the accuracy and timeliness
of credit risk analysis while simultaneously making it more transparent and
easier to audit in a world that is ever more concerned with the explainability
and fairness of the actions undertaken using Artificial Intelligence.
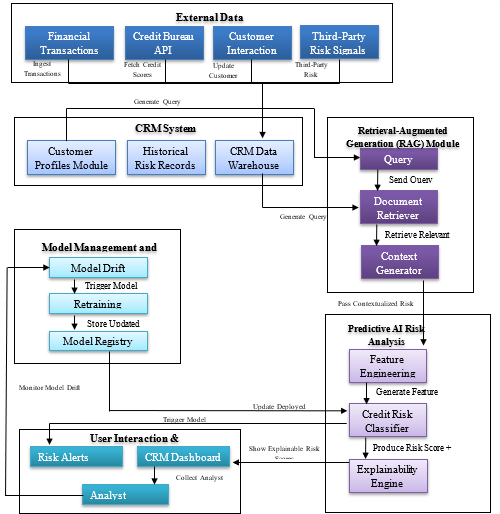
Figure 1: System Architecture for Enhancing Credit Risk Analysis in Financial CRMs using RAG and Predictive AI.
3.2. Data sources and preprocessing for CRM
systems
The modern approach to credit risk
analysis in connection with the use of modern CRM systems involves using many
various but high-quality sources of information. The proposed framework
receives data from conventional finance sources and new advanced sources. The
external data include the financial transaction databases, credit bureau APIs,
customers’ interaction logs and third-party risk signals. Each provides value
for real-world spending patterning, scoring normalized for risk benchmarking
and customers’ raw interacting patterns and sentiment. However, preprocessing
is always required before the datasets can be used in analytical models. Data
preprocessing techniques are practiced to deal with problems related to missing
data, inconsistent data format and errors in entries. Normalization and feature
scaling normalize or scale the numbers involved in order to bring all
attributes from different sources to the same order. Thus, for the case of
unstructured data like customer logs/risk alerts, features are derived from
them using natural language processing (NLP). Furthermore, the entity
resolution methods help to connect the customer data from various sources and
enrich the consolidated customer view in the CRM Data Warehouse. This is very
important to enhance the quality of the data to allow subsequent processes,
such as the RAG module and the Predictive AI Engines, to run without
interruption.
3.3. Retrieval-augmented generation (RAG)
for contextual credit analysis
The RAG module is critical in changing the
CRM data from passive to active and contextual credit risk information. In
contrast to other dialogue modular systems, RAG does not contain pre-stored
information required for the credit assessment. Still, it dynamically builds
its context from real-time documents important for the current assessment task.
When the Query Encoder component receives a query that can be consistent or
created by the risk analyst based on some observed situation, the component
takes the representation of an analyst’s query and the context of the customer.
This vector is then given to the Document Retriever, which retrieves the
updated risk documents relevant to the identified sources from both internal
and external sources that have been indexed. The documents are then compiled
into information packages by the Context Generator, including recent trends in
finance behavior, regulation changes and the macroeconomic environment. In this
way, RAG excludes the impact of such key issues as high dependence on outdated
information and high probabilities of appearing hallucinations, which are
inherent to the work of traditional language models. This real-time
contextualization makes it easier to get updates about the borrower's current
risk environment, making credit risk scores timelier and more accurate for
financial decision-making.
3.4. Predictive AI models for risk scoring
The Predictive AI Risk Analysis engine
performs the classic quantitative risk rating if the input is contextualized. In
order to start with, there exists the Feature Engineering Engine that works by
converting the big contextual data into vectors suitable for the efficiency of
machine learning models. The interactions of features, which include feature
crossing and embedding layers as well as the use of feature extraction tools
such as principal component analysis (PCA). The core classifier is an ensemble
of XG Boost, deep neural networks (DNNs) and decision trees for improved
accuracy and stability of the model. After the credit risk score has been
computed, the Explainability Engine adds brief explanations to its output for
human understanding. The explanations on risk assessment are based on methods
such as Shapley value decomposition and attention heatmaps that focus on the
important features and events that led to the final decision. It also assures
compliance with the legal aspects, thus increasing the level of trust between
the lenders and borrowers and, at the same time enables the analyst to arrive
at quicker decisions about the loans to offer. The proposed model architecture
of the hybrid allows the avoidance of overfitting, the ability to detect new
risk patterns and integration with continuous learning.
3.5. Integration strategy into financial CRMs
Seamless integration into existing
financial CRM systems is critical for maximizing the utility of the proposed
framework. This way, the architecture is designed for modular deployment where
Financial Institutions can implement the framework and components in stages
depending on their technological advancement and business needs. The main role
of the CRM Data Warehouse is to provide mediation and integration, receive data
from the external data ingestion layers and the RAG module and work with the
predictive analytics engine and users’ dashboards through APIs only. These are
procedures such as encryption, access control and logging to ensure that customer’s
information is secured throughout the data flow process. In order to provide a
good user experience, the Risk Alerts Module and the UI for the CRM Dashboard
contain alerts, clickable heat maps and search functions to help the user find
a specific customer. Notably, the Analyst Feedback Collector is a part of the
CRM, which helps update the model, achieving the human-in-the-loop model and
improving the level of risk scores. Using the Model Management and Feedback
Loop means that models are updated as often as needed based on market changes.
Using xAI means that outcomes obey the Fair Credit Reporting Act (FCRA) and
Basel III benchmarks. Therefore, the integration aims to enhance incumbent CRM
solutions whilst avoiding service interruption to facilitate the building of a
smarter, more flexible and less vulnerable credit risk management framework.
4.
Implementation Details
4.1. Technology stack and tools used
The technologies used in implementing the
proposed credit risk analysis system are based on the technological stack that
will allow for scalability and performance of the analysis, as well as how
easily the technology can be integrated with the overall system13-16. For data storing and processing,
cloud relational databases like Amazon RDS and Azure SQL are used and data
repositories such as Amazon S3 are used for dealing with the large amount of
semi-structured transaction logs and interaction data. Data preprocessing is
conducted in Python with the help of Pandas, NumPy and spaCy for manipulating
both structured and unstructured data. The Retrieval-Augmented Generation (RAG)
module is developed using Hugging Face’s Transformers and FAISS (Facebook AI
Similarity Search) to index documents and passages. For the predictive AI
models, suitable frameworks like XG Boost, TensorFlow, Py Torch, et cetera are
used to develop and deploy the machine learning models to handle high
dimensional feature space. The tools used for developing the interactive CRM
interface and dashboards include React.js, While the CRM platforms used are
force.com (Salesforce) and Microsoft dynamics via RESTful APIs. Kubernetes is
used to manage the containers of the services to easily deploy and scale them,
while tools such as ML flow are used to track the models throughout the
development process (Table 1).
Table 1:
Technology Stack Used for Enhancing Credit Risk Analysis in Financial CRMs
|
Component |
Technology/Tool |
Purpose |
|
Data Ingestion |
Apache
Kafka, ETL Scripts |
Real-time
data streaming & transformation |
|
Preprocessing |
Pandas,
NLTK, spaCy |
Cleaning
structured/unstructured data |
|
Retrieval Layer |
ElasticSearch,
FAISS |
Fast
document/vector retrieval |
|
Language Model |
OpenAI
GPT / BERT / T5 |
Text
generation and embedding |
|
ML Framework |
PyTorch,
TensorFlow |
Model
training and deployment |
|
Visualization |
Plotly,
Tableau |
Interactive
dashboards |
|
Compliance Tools |
SHAP,
LIME, Differential Privacy |
Model
explainability and data protection |
4.2. Model training and fine-tuning
processes
The processes of model training and model
fine-tuning are extremely important in order to enhance the ability of the
system to predict accurately as well as to be robust over the long run. First,
the baseline models are trained on historical credit performance data in which
default, delinquencies, repayment history and other aspects are labelled. Thus,
for the Retrieval-Augmented Generation module, large language models are
trained on the financial and credit report, regulatory bulletins and credit
analyst notes to attune the model to process financial jargon and focus on that
particular type of language. Fine-tuning, on the other hand, works under
transfer learning methods where the transformer models are trained on some
other specific datasets with small learning rates during training to avoid the
issue of catastrophic forgetting. Techniques such as grid search and Bayesian
optimization are used to finalize model structures so that the chosen
performance measures undergo optimization: AUC-ROC and the balance between
precision and recall.
Furthermore, to cater for the problem of model drift that arises during the deployment process, a continuous training process is set up. This pipeline takes newly acquired risk events and feedback from the analysts to improve and update the models in the pipeline without needing to retrain the model from scratch. This technique enhances adaptability without interrupting operations.
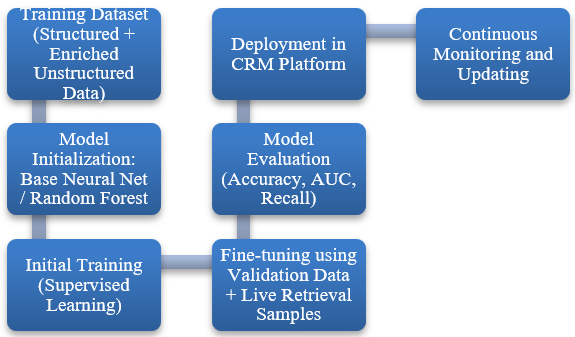
Figure 2: AI Model Training and Fine-tuning Workflow.
4.3. Handling data privacy and compliance
Given the sensitive nature of financial
and customer data, robust strategies for handling data privacy and compliance
are integral to the system’s architecture. Customer-identifiable information
(CII) is also preserved through the Secure Sockets Layer or Transport Layer
Security protocol at both storage and transit with the use of protection
schemes like Advanced Encryption Standard ciphering or AES-256 and Transport
Layer Security stand TLS 1.3. RBAC is implemented at different levels within
the system whereby only authorized people are allowed access or make changes to
the sensitive data17-20. As data
is removed in tasks where possible, data anonymization and tokenization are
applied where there is a need to replace specific data during the training
phases. In order to ensure GDPR, CCPA and FCRA compliance, settings of audit
trails and consents are automated. Audits of data access and penetration
testing, as well as employing the services of third-party security assessors,
are performed to reduce these risks ahead of time. The robust explainability
architectures developed into the appropriately selected AI solutions can also
support the reporting requirements to the regulators and enable reporting for
the ruling for adverse consumer credit decisions.
5.
Experimental Setup and Results
This section describes the experimental
setting that will be employed to assess the performance of Retrieval-Augmented
Generation (RAG) in credit risk analysis against traditional machine learning
methods. It is detailed in the experiments that predictive performances,
insensitivity to imbalanced classes and abilities for dynamic updating of
models based on borrower information have been considered.
5.1. Dataset description
In order to enhance the validity of the
study, this research employed two major data sets, The ChinaZJB SME dataset and
several credit datasets from UCI. The ChinaZJB SME dataset stems from the
annual loan ledger of a Chinese commercial bank and features the information of
1,329 SMEs, out of which 108 are defaulting and 1,221 are non-defaulting. The traditional
analysis involves reports on financial ratios, additional loan details, credit
rating and non-financial parameters. First of all, serious problems of class
imbalance are notable as, on average, there is one default for 11 non-defaults.
For assessing robustness across different environments, the work used UCI
benchmark datasets. These comprise the Polish bankruptcy data (versions 1 to
3), the Australian credit approval data and the Taiwan credit card default data
(Table 2).
Table 2:
Summary of Datasets Used for Model Evaluation.
|
Dataset |
Samples |
Defaults |
Non-Defaults |
Imbalance
Ratio |
|
ChinaZJB
(SMEs) |
1,329 |
108 |
1,221 |
1:11 |
|
UCI Polish 1 |
7,026 |
275 |
6,751 |
1:25 |
|
UCI
Australian |
690 |
307 |
383 |
1:1.25 |
5.2. Evaluation metrics
In order to provide a holistic assessment
of model performance, multiple evaluation metrics were utilized. Accuracy
determined the number of correct classifications concerning the total number of
cases. At the same time, precision assessed the capability of minimizing false
positives by looking at the number of true positives against the total
predictions made. Regarding recall, the emphasis was on the ability to detect a
reasonable number of defaulters; it involved determining the percentage of
actual defaulters that were accurately captured. The F1 Score, a combination of
precision and recall indicators, was particularly used to analyze the results
for markers for the imbalanced datasets. The AUC-ROC model was used to check
the model's capacity in classifying between a defaulter and a non-defaulter
using different threshold levels.
5.3. Baseline comparisons
The following compares the traditional
machine learning models and the developed RAG-enhanced credit risk system. For
training information only that was in structured data format, we had Random
Forests, Neural Networks, Support Vector Machines (SVMs) and Logistic
Regression models (Figure 3). At the same time, RAG systems used the
data in structure formats plus dynamic data from unstructured databases (Table
3).
Table 3:
Performance Comparison of Traditional Machine Learning Models.
|
Model |
Accuracy |
AUC-ROC |
Precision |
Recall |
F1
Score |
|
Random Forest |
93% |
0.94 |
0.91 |
0.88 |
0.90 |
|
Neural
Networks |
91% |
0.92 |
0.89 |
0.86 |
0.87 |
|
Support
Vector Machine (SVM) |
89% |
0.88 |
0.82 |
0.84 |
0.83 |
|
Logistic
Regression |
84% |
0.79 |
0.78 |
0.76 |
0.77 |

Figure 3:
Graphical Representation of Performance Comparison of Traditional Machine
Learning Models.
5.4. Performance analysis of RAG vs traditional
models
The introduction of Retrieval-Augmented
Generation into the credit risk assessment pipeline yielded substantial
improvements across all major evaluation metrics. Concerning the ChinaZJB SME
classification task, the RAG-enhanced systems could provide results of around
95 % accuracy, which was much higher than the baseline Random Forest. This
improvement mainly came from behavioral data of borrowers, transaction
stability and sentiments from social media, which gave a real-time indication
of the health of the borrowers.
RAG models achieved a better AUC-ROC of
0.96 than the Random Forests, with an AUC-ROC of 0.94 only. Indeed, this level
of discriminative power is explained by the capacity of RAG to integrate
real-time macroeconomic factors (such as employment statistics or
sector-specific information) when it is evaluated. Further, RAG systems kept a
precision of 0.93 and a recall of 0.90. Thus, false positives were very low
while the right clients at risk were identified. Significantly, RAG was able to
claim that their capacity to process external big data contributed greatly to
the issue of class imbalance. These rates show the effectiveness of
RAG-enhanced systems in contrast with the previous models and these had an
increase of approximately 22% of the minority class (default prediction), which
can help in the early identification of high-risk customers. Thus, enhancing
the adaptive context-awareness of credit risk prediction requires the integration
of the retrieval mechanisms with the machine learning model for more efficient
credit risk prediction.
6.
Discussion
The corresponding analysis of the results
obtained from the experiment showed that using the Retrieval-Augmented
Generation (RAG) in financial CRM systems significantly improves credit risk
assessment. RAG makes models have situational awareness, as they can update
their behavioral data of a specific borrower and macroeconomic indicators in
real-time, which is not characteristic of traditional AI. This real-time
contextualization also enhances the marksmanship and recall, as well as the
identification of early warning signs of borrower’s behavior, which will help
to promote the effectiveness of risk management. Especially for imbalanced data
sets where defaults are few but important for detection, like our ChinaZJB, the
RAG-augmented models have been found to have 22% higher Minority Class Recall,
which can revolutionize how institutions could contain credit risk.
RAG-enhanced systems lead to enhanced
performance levels; however, it brings new challenges. Managing external data
acquisition in real-time processing truly calls for a well-organized,
well-equipped framework, better and stringent validation and verification
principles and considerable and sophisticated query optimization measures to
achieve both reliability and control of latency. However, privacy, compliance
(i.g.., GDPR, CCPA) and ethical usage of unstructured data will always be
critical for maintaining regulators’ approval and clients’ trust.
Interpretability mechanisms such as explainability engines are even more
important when the model’s features or predictions depend on information that
can change in a short time, like social media updates. Financial institutions,
hence, have to consider the two elements of superior and optimum prediction as
they also foster openness, responsibility and regulation of artificial
intelligence-based decisions. Transitioning from RAG into predictive credit
risk analysis is a great leap towards the next generation of financial CRM
systems. This not only helps firms predict defaults more accurately but also
makes them improve constantly in adjusting to the economic conditions that
constantly change. Future work in this regard might consider a refinement of
the retrieval approach, the application of reinforcement learning for better
risk management and the use of federated learning for improved data privacy
during the usage of downstream external data sources.
7.
Future Work
The future advancements in the retrieval
systems will enhance the efficiency, precision and relevance of the information
retrieved during credit risk assessments. Many current approaches based on RAG
models have issues such as high retrieval latency and noise when it comes to
unstructured information. This can be achieved with the help of using such
techniques as dense passage retrieval, knowledge graphs and multi-hop retrieval
chains of the sources. Moreover, the inclusion of some kind of reinforcement
learning-based feedback option can be introduced that would help make the
learning process in the given retrieval systems dynamic by revealing which
sources are most trustworthy and therefore more contextually relevant and
helpful, for different types of borrowers by improving the precision and speed
of risk predictions.
Personalized credit risk modelling is
another area of growth in the field in the future. Standard credit scoring
procedures provide little distinction between borrowers in the same risk
profile or age. However, the next-generation systems are ideally positioned to
create even truly accurate risk scores using RAG combined with much more
detailed borrower characterization targeting not only transactional behavior,
real-time social media phenomena and even borrowers’ economics. It would
facilitate accurate differentiation of credit products, customized setting of
the interest rate structures and the ability to monitor early warning signs of
firms in distress for each customer, thus enhancing customer satisfaction and
portfolio performance. However, the general idea of applying RAG and predictive
AI in other aspects of financial decisions goes further than credit risk
analysis. Some applications include investment advisory services, anti-money
laundering (AML) tools, insurance and claims underwriting, particularly when it
involves real-time retrieval. The following are some examples: active
management of investment portfolios based on real-time data on geopolitics
events and the use of the Internet to adjust insurance premiums based on
lifestyle data. It is believed that as information retrieval systems continue
to grow in terms of their capabilities in terms of scalability and context
sensitivity, there will be significant growth in the use of these systems
within the financial sphere to make more responsive or more data-driven
decisions.
8.
Conclusion
This study demonstrates the transformative
potential of integrating Retrieval-Augmented Generation (RAG) with predictive
AI models in the context of credit risk analysis for financial CRM systems. By
Incorporating RAG, methods improve the modelling precision and recall and
reduce sensitivity to class imbalance about more conventional machine learning
solutions achieved by combining structured financial data and real-time
external data retrieval. Hence, RAG’s capability of responding to borrower behaviors
and macroeconomic changes makes it a critical tool in applying agile and smart
credit risk management strategies.
RAG also incompletely solves important
problems of descriptive AI, such as the knowledge cutoff problem and static
risk profiling. Applying current values of the market changes in regulations
and evaluating the borrowers ‘behavior signals lets the financial institutions
adapt quickly to economic conditions. However, to adopt and implement RAG
systems, revision of data governance, model explainability and regulating
requirements are necessary to enhance trust. In conclusion, this paper presents
RAG-enhanced predictive AI as a symbolic direction toward improving the
financial decision system. Future research development will also focus on improving
the retrieval technique, communicating risk assessment and bringing horizons to
other segments of the financial industry. That way, such changes can make a
difference for financial institutions to deliver higher accuracy, fairness and
efficiency in risk assessment and client engagement.
9.
References
- Wang
Z. Artificial Intelligence and Machine Learning in Credit Risk Assessment:
Enhancing Accuracy and Ensuring Fairness. Open Journal of Social Sciences, 2024;12:
19-34.
- Giudici
P, Hadji-Misheva B, Spelta A. Network-based credit risk models. Quality
Engineering, 2020;32: 199-211.
- Mays
E. Credit risk modelling: design and application. Global Professional Publishing,
1998.
- Aziz
S, Dowling M. Machine learning and AI for risk management. Springer
International Publishing, 2019: 33-50.
- Pedron CD, Picoto WN,
Dhillon G, et al. Value-focused objectives for CRM system adoption. Industrial
Management & Data Systems, 2016;116: 526-545.
- Paltrinieri
N, Comfort L, Reniers G. Learning about risk: Machine learning for risk
assessment. Safety Science 2019;118: 475-486.
- Hegde
J, Rokseth B. Applications of machine learning methods for engineering risk
assessment- A review. Safety Science, 2020;122: 104492.
- Sharma
A, Singh UK. Modelling of smart risk assessment approach for cloud computing
environment using AI & supervised machine learning algorithms. Global
Transitions Proceedings, 2022;3: 243-250.
- Zhang
B, Yang H, Zhou T, Ali Babar M, Liu XY. Enhancing financial sentiment analysis
via retrieval augmented large language models, in Proceedings of the fourth ACM
international conference on AI in finance, 2023: 349-356.
- Pan J, Yang Q, Yang Y, et al.
Cost-sensitive-data preprocessing for mining customer relationship management
databases. IEEE Intelligent Systems 2007;22: 46-51.
- Peppard
J. Customer relationship management (CRM) in financial services. European Management
Journal 2000;18: 312-327.
- Siddiqi
N. Intelligent credit scoring: Building and implementing better credit risk
scorecards. John Wiley & Sons, 2017.
- Ryals
L, Payne A. Customer relationship management in financial services: towards
information-enabled relationship marketing. Journal of strategic marketing, 2001;9:
3-27.
- Zheng
H, Shen L, Tang A, et al. Learn from model beyond fine-tuning: A survey, 2023.
- Kamath
CN, Bukhari SS, Dengel A. Comparative study between traditional machine
learning and deep learning approaches for text classification. In Proceedings
of the ACM Symposium on Document Engineering, 2018: 1-11.
- Chauhan
NK, Singh K. A review of conventional machine learning vs deep learning. In
2018 International Conference on Computing, power and communication
technologies (GUCON), 2018: 347-352.
- Delamaire
L. Implementing a credit risk management system based on innovative scoring
techniques (Doctoral dissertation, University of Birmingham), 2012.
- Siddiqi
N. Credit risk scorecards: developing and implementing intelligent credit
scoring. John Wiley & Sons, 2012;3.
- Wu TC, Hsu MF. Credit risk
assessment and decision-making by a fusion approach. Knowledge-Based Systems, 2012;35:
102-110.
- Doumpos M, Lemonakis C, Niklis D, et al. Analytical techniques in the assessment of credit risk. EURO advanced tutorials on operational research, 2019.