FDIC Resolution & Regulatory Submissions: Traceable, Reconciled Data Pipelines for Large Financial Institutions
Abstract
Resolution planning and high-frequency regulatory submissions have
become critical supervisory expectations for systemically important financial
institutions. Regulators such as the Federal Deposit Insurance Corporation
(FDIC) increasingly require institutions to demonstrate not only accuracy and
timeliness, but also traceability, reconciliation and audit-ready lineage
across complex enterprise data environments. Traditional regulatory reporting
architectures-often fragmented, manual and opaque-are insufficient to meet
these expectations, leading to reconciliation breaks, delayed submissions and
extensive regulator follow-up queries. This paper presents a reconciled,
traceable data pipeline architecture designed to support FDIC resolution
planning and recurring regulatory submissions for large financial institutions.
The proposed framework integrates controlled reference data, dual-control
reconciliations, deterministic aggregation logic and reproducible reporting
outputs. Emphasis is placed on end-to-end lineage, from source systems through
transformation layers to regulatory schedules, enabling transparent
auditability and rapid regulator Q&A response. The methodology incorporates
standardized ingestion patterns, metadata-driven transformations, reconciliation
checkpoints at each processing stage and a rigorous testing matrix spanning
unit, integration, regression and scenario testing. A governance-aligned
control framework ensures segregation of duties, change management discipline
and submission certification accountability. Results from an enterprise-scale
implementation demonstrate measurable improvements, including reduced manual
adjustments, accelerated submission timelines, improved data quality metrics
and enhanced regulator confidence. The findings indicate that reconciled
pipelines are foundational to sustainable compliance, particularly under
increasing submission frequency and supervisory scrutiny. This paper
contributes a practical, scalable model for regulatory data engineering in the
context of FDIC resolution requirements.
Keywords: FDIC resolution planning, Regulatory reporting, Data
lineage, Reconciliation controls, Audit-ready pipelines, Financial data
governance
1. Introduction
1.1. Background
Following the world
financial crisis, the regulatory authorities the world over came up with
heightened resolution planning criteria to reduce the systemic risk posed by
large and complex financial institutions1,2.
The Federal Deposit Insurance Corporation (FDIC) in the United States requires
the resolution plans (also known as living wills), to be submitted that show
how a firm might be resolved in an orderly fashion without assistance by the
taxpayers. Originally developed as more or less fixed documents, these plans
have turned into very data-intensive and recurring regulatory filings that
require regular operational discipline. These submissions have highly increased
their range to incorporate granular balance sheet breakdowns, liquidity
measures and legal entity exposures, derivatives stands and additional vital
financial and risk information. To satisfy these needs, it is important to have
regular and reconciled flows of data in many domains, such as finance, risk,
treasury and operational systems, each of which could have its own data
structures and reporting conventions. Regulators have become more attention
able to the fact that compliance is not only a question of the number of
figures on the balance sheet but they also need to have transparent, traceable
and reproducible reporting frameworks. This implies that the reported
aggregates should be supportable, have an evident audit trail of how the data
copy came to the aggregation system through transformation and submission. This
in practice necessitates a complete data governance, centralized reference data
management, deterministic transformation and aggregation logic and sound
reconciliation processes. The regulatory emphasis on traceability and
reproducibility is an expression of a wider supervisory aim, namely to make
sure that firms can adequately demonstrate operational resilience and provide
timely and reliable information under normal and extreme circumstances so as to
enhance the stability of the financial system overall.
1.2. Needs of FDIC resolution &
regulatory submissions
The large financial institutions are highly demanded in terms of operational accuracy and governance structures by the FDIC resolution planning and the regulatory submissions that accompany the planning process3,4. The needs can be classified in several major areas (Figure 1):

Figure 1: Needs of FDIC
Resolution & Regulatory Submissions.
- Comprehensive data integration: Resolution plans
need data of different functional area to be aggregated such as finance, risk,
treasury and operations. Multiple sources with different schemas, data
standards and frequencies of updates, which consist of different institutions,
need to be combined in a unique reporting pipeline. This integration helps to
assure that all the regulatory submission is consistent, complete and aligned
with the statutory financial and risk exposures of the institution.
- Data accuracy and reconciliation: In order to have the
confidence of the regulators, precise and reconciled data is essential. The
FDIC and other oversight regulators anticipate that the reported figures,
including balance sheet decompositions, liquidity positioning as well as legal
entity exposures, be aligned not only within individual systems but also
between and among systems. Aggregated data integrity requires multi-dimensional
reconciliations, which encompass legal entities, product lines, currencies and
exposures to counterparty to prompt inconsistencies capable of attracting
regulatory enquiries.
- Traceability and lineage: The regulators are
placing more importance on traceability and explainability of the reported
data. All the figures supplied in a resolution plan should be identifiable to
source systems, documented transformations, aggregation rules and reference
data mappings. Such a degree of data lineage can guarantee submissions can be
reproduced, can be reviewed by an audit or other supervisors and makes all
reported metrics more defensible at a glance.
- Operational controls and governance: It also needs
powerful governance structures to contain the confusion and danger of repeated
submissions. The key requirements that institutions should introduce are the
controlled reference data hubs, approval workflows, version control and
effective-dated change management. Concerted balances, regularized verification
process, on-format testing cycle are needed in order to ensure consistency,
less manual intervention and measurement of the operational risk.
- Timeliness and regulatory compliance: The submission of
high-frequency regulatory submissions requires timelines. The institutions
should have in place procedures that enable points of data freeze, sign-offs of
reconciliation, management certification and submission in a timely manner. It
is imperative to meet these deadlines and be able to achieve the accuracy and
completeness of the data so as to be able to retain regulatory trust and show
preparedness to operate under the possible resolution scenarios. Taken together
these requirements point to the fact that FDIC resolutions and regulatory
submissions cannot be viewed as mere reporting activities, but in order to
facilitate transparency, reproducibility and quick regulatory reaction a
well-developed, integrated and auditable data infrastructure is necessary.
1.3. Regulatory submissions: Traceable, reconciled
data pipelines for large financial institutions
Regulatory
submissions in relation to large financial institutions have become extremely
complicated activities, which demand more than mere data reporting5,6. More and more certainly, regulators like
the FDIC and other supervisory agencies are demanding not only numerical
accuracy but also traceability in all reported metrics in addition to
reproducibility and reconciliation. This has brought about a need to come up
with traceable, reconciled data pipelines that could combine information across
diverse functional areas such as finance, risk, treasury and operations. These
pipelines are the foundation of regulatory reporting in which institutions are
able to generate quality and defendable data, both with consistency and
efficiency. Traceable data pipes are end to end, meaning that each figure that
is reported can be tracked to the underlying systems, transformations and
aggregation logic. It involves comprehensive lineage of transactional data,
reference data and calculation procedures so that regulators need not have to
question reported measures since they can self-test and recreate them.
Traceability minimizes chances of errors, enhances auditability and enables
quick response to supervisory questions especially in the context of resolution
planning where real time and correct reporting is crucial. The reconciliation
in the given pipelines is complementary since it ensures the data survey
evenness among various aspects including legal entities, product lines,
currencies and counterparty IEs. Multi-layered, automated reconciliations
(source-to-ingestion, ingestion-to-transformation and aggregation-to-output)
are effective to identify discrepancies at an early stage as well as avoiding
the spread of errors. This will reduce the state of man-hands, operational risk
and expediture and the submission cycles, making institutions able to meet the
arm-twisting regulation time frames without quality of data being compromised. Also,
the strong governance and control systems, such as centralized reference data
control, aggregation logic versions and formal approval processes, strengthen
the pipeline integrity. Through the integration of traceability, reconciliation
and controls into the architecture, the financial institutions, which are
large, can make sure that the regulatory submissions made by them are not
solely accurate but they are also auditable, repeatable and in line with the
changing supervisory expectations. Such pipelines can be used to ensure that
regulatory reporting is resilient and proactive rather than reactive and the report includes both compliance and
operational efficiency.
2. Literature Survey
2.1. Regulatory reporting architectures
The regulatory
reporting environment has changed dramatically and the sphere of
report-oriented and siloed process to support and interpret data-driven
architectures7-9. Principles
supporting effective risk data aggregation and risk reporting (BCBS 239) by the
Basel Committee on Banking Supervision are foundational directions that state
essential requirements in regards to the accuracy, completeness, timeliness and
flexibilities of the data. These doctrines have had a potent power in shaping
patterns of thinking in supervisory and industry designs. These requirements
are however extensively addressed in the literature at a conception level which
has little to say on how companies can practically implement them in complex
legacy systems. White papers on industry and publications by vendors often
recommend centralized regulatory data lakes or enterprise reporting systems,
whereas in fact the reconciliation, control and governance provisions on which
such resolution planning and supervisory scrutiny will depend.
2.2. Data lineage and auditability
Data lineage and
auditability Studies on data lineage and auditability are mainly concerned with
metadata management, provenance tracing and technical traceability of data
pipelines. In financial services, though, lineage has an extra regulatory
aspect: financial institutions are expected to be able to justify, defend and
recreate any given reported figure of business and regulatory substance.
Supervisory expectations are larger than system-to-system traceability with
clarity of data ownership, logic of transformation and compliance to required
regulatory definitions. Current lineage models often focus on the technical
processes at the expense of resolving the gap between the raw data, business
semantics and regulatory interpretation, making them ineffective with
regulatory reporting and examination needs.
2.3. Reconciliation frameworks
Literature on
reconciliation also focuses on the fact that it is the financial control
processes that include the reconciliation of sub-ledger balances against the
general ledger to enhance accounting integrity. These strategies are quite
established in the reporting of financials, but they are not adequate in terms
of regulatory resolutions filings, which must be reconciled on various levels,
including legal entities, product, currency and counterparty hierarchies. The
resolution-related data also should be in a position to reconcile with risk,
finance and treasury areas and this is usually on a tight time schedule. The
literature does not have sufficient advice on how to expand the reconciliation
frameworks past accounting constructs in order to facilitate regulatory
submissions where heterogeneous data source and supervisory viewpoints are
aggregated.
2.4. Gaps identified
A weakness in the
literature on regulatory architecture, data lineage and data reconciliation, is
the lack of a holistic, end-to-end framework, integrating governance, controls,
lineage, reconciliation, plus testing into a single reporting pipeline on
regulations. The current research and industry trends would look at these factors
singly, thus coming up with piecemeal solutions that can never pass the
scrutiny of the supervisor. It is interesting to note that scholarly or
practitioner literature is scarce that describes operationally proven
architectures that are explicitly aligned with expectation of resolution
authority, e.g., the expectations of the FDIC. The paper aims to fill this gap
with a set of proposed, unified, regulator-friendly architecture that is based
on reality experience in implementation.
3. Methodology
3.1. Architectural overview
The proposed
regulatory reporting pipeline will be developed as a layered architecture,
which will enhance regulatory traceability, control and modularity10-12. The levels have their own functions as
well as help in end-to-end data lineage, reconciliation and governance. This
isolation of concerns makes it scalable, review of by supervisors is made easy
and it makes it possible to have an individual part of the reporting process
evolve without jeopardizing the integrity of the entire process (Figure 2).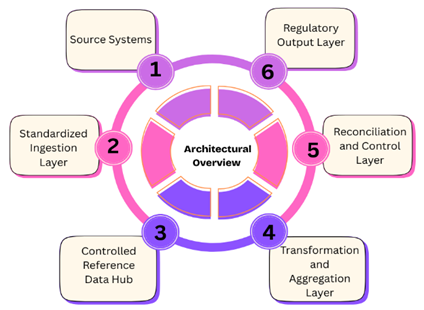
Figure 2: Architectural
Overview.
- Source systems: At the heart of the
architecture is a set of source systems that are the core finance, risk and
treasury platforms to create authoritative transactional level and position
level data. The data structures, definitions and the update rates are often not
homogeneous in these systems because they are usually optimized to provide
operational processing, as opposed to regulatory reports. The architecture
views the linking of source systems as systems of record whereby original data
attributes are retained and required metadata necessary to support both
traceability and auditability of the downstream reporting lifecycle are
captured.
- Standardized ingestion layer: Standardized
ingestion layer is the layer that is in charge of sourcing out data in the
source systems and transforming it to a consistent and normalized format.
Initial validation checks, schema conformity, completeness and simple data
quality checks, are enforced in this layer, before the data is taken into the
regulatory pipeline. The architecture ensures the downstream is kept simple by
imposing common standards of ingestion and only allows data of the right format
to pass through the system in all ways such that its technology and governance
requirements have been defined in advance.
- Controlled reference data hub: The controlled
reference data hub is a central repository of important reference data that
contains legal entity hierarchy, product taxonomy, currency code, side of the
counterparty and so on. This layer gives uniformity of reference data within
all the processes of reporting and facilitates regulatory expectation of
similar interpretations of areas of significance. Reference data are placed
under strong governance, versioning and approval workflows to make changes
controlled and allow cumulative reproducibility of regulatory submissions.
- Transformation and aggregation layer: The transformation
and aggregation layer uses business rules, regulatory logic and calculation
methods in order to transform normalized source data into reportable metrics.
This layer facilitates intricate changes, such as currency converts,
risk-weighting, aggregations on legal entity levels and much more. Every logic
of transformation is recorded, parametrized and controlled to ensure
transparency and allow someone to trace the reported indices into their
underlying causes (regulators and internal stakeholders).
- Reconciliation and control
layer: The reconCIlation
and control layer is used to conduct organized verifications to confirm that
transformed data is valid. This involves balancing regulatory aggregates to
fund totals and ensuring consistency between such dimensions as legal entities
and products and unexplained variances. Hidden controls, tolerance limit and
exception management processes have been instituted to verify that
inconsistencies are investigated, registered and addressed before submission to
the regulatory authorities.
- Regulatory output layer: Regulatory output
layer will generate final submission ready reports and data files in a format
mandated by regulatory bodies. This layer can contain jurisdiction specified
templates, frequency of submission and validation regulations without detriment
of the underlying governed data set. Outputs are also completely audible,
reproducible and maintained with evidence of lineage and control, which allows
an institution to react properly to supervisory investigations and inspections.
3.2. Reference data controls
Reference
information, such as legal entity structures, product hierarchies and
counterparty classification, among other important dimensions13,14, contributes to the basic role of
regulatory reporting and resolution planning. The proposed architecture has the
reference data being consolidated through a controlled hub which acts as the
single source of authority to all the downstream regulatory processes. In
centralization, an imbalance manifested by duplicate or locally managed
reference datasets and disparity in the interpretation of key reporting
dimensions within the finance, risk and treasury boundaries is removed. As it
is a highly regulated data where the regulating body considers reference data
as defining the boundaries of aggregation and the factor to report on,
well-built governance and control systems are directly integrated in its
lifecycle management. All documentary data items will be tightly versioned and
effectively date to aid historical reproducibility of regulatory submissions. A
change is given the version identifier and time that it was made and the
business rationale that it was made and it is impossible to rearrange the data
that was actually used as references by any previous submission that was made
by the institution in history. This is essential to answer supervisor
questions, remediation work and lookback analysis, especially in resolution
planning, where the regulators can demand re-submission or recalculation of
past numbers in previous organizational set-ups. Reference data change
management is a formal work flow that involves two approvals, on both business
and data governance fronts. Changes are impacted to determine downstream
impacts on the logic of aggregation, its reconciliations and its regulatory
output before being further advanced to production. Segregation of duties takes
place through automated controls that cannot make alterations that are
unauthorized and also reduce operational risk. Besides, periodic attestations
and data quality checks are conducted to confirm completeness, accuracy and
consistency of reference data to outside sources and internal policies. The
architecture will facilitate the reproducibility of supervisory-perspective
regulation reports by integrating governance, auditability and reproducibility
into reference data management so that regulation reports are technically
correct and defensible on a supervisory basis. These controls, directly,
reinforce regulatory requirements of transparency, consistency and
explainability and they constitute an important enabler of dependable, scalable
and regulator-compliant reporting procedures.
3.3. Dual-control reconciliations
There are embedded
dual-control reconciliations in the regulatory reporting pipeline to verify the
integrity of the data it contains, its completeness and its defense to the
regulatory scrutiny15,16. Instead of
leading to a reconciliation as a single end-stage operation, the architecture
deploys checks at the transition points that are critical and independent
control perspectives are applied on the same stage. This method will allow
identifying the problems with data early enough, reduce the spread of mistakes
and leave documents by which they will be able to audit that they have checked
the reported numbers throughout the entire data lifecycle.

Figure 3: Dual-Control
Reconciliations.
- Source-to-ingestion reconciliation: The reconciliation
matches the data obtained by source, to ingestion ensures that all and all the
data extracted in the finance, risk and treasury source systems is completely
and purely mirrored in the standardized ingestion layer. Checks in this level
are based on the number of records, critical financial sums and such attributes
as legal entity, product and currency identifiers. The architecture will ensure
that no data is lost, copied or changed in the extraction and transfer process
since it reconciling the data ingested with source system control totals.
Errors are recorded and examined before reduced to downstream processing and a
firm basis on future transformations is established.
- Ingestion-to-transformation
reconciliation: Ingestion-to-transformation reconciliation is used to verify the
use of normalization rules and business logic when data is transferred to the
transformation and aggregation layer. The element of this stage here is to
determine the consistency of standardized data items following enrichment,
reference data merger and preliminary calculations. The controls involve check
of balance, dimensional completeness and verification of rules of
transformation against approved specifications. External validation of transformations
works well to ensure consistency in business and regulatory logic used in the
transformation processes and periodicity of business reports.
- Aggregation-to-output reconciliation: Aggregation-to-output
re-convergence is used to verify that the aggregated measures and regulatory
reports represent the underlying transformed data correctly. This involves
balancing regulatory totals to finance control figures, certifying
cross-dimensional consistency (legal entity/ product roll-ups) and certifying
consistency to regulatory templates. Tolerance levels and escalation protocols
are used to deal with acceptable tolerances and enquiry into abnormalities.
This last reconciliation levels offers a secure ensuring that the regulatory
submissions are indeed complete and are accurate with a definite audit trail
that links to the source and the output.
3.4. Deterministic aggregation logic
Deterministic
aggregation logic is an overarching design concept of the proposed regulatory
reporting architecture and acts as a guarantee that reported metrics are always
based on, can be fully explained and reproduced across reporting periods17,18. The aggregation policies are all
rule-based and parameterized and the business and regulatory logic is clearly
sped out and not hard-coded in an ad hoc script or custom tunings. Such a
strategy negates the use of discretionary overrides, which often introduce
operational risk and raise doubts among the supervisors and executes
standardized computations which are readily verifiable and effectively
reproducible. The aggregation rules are deterministic in nature i.e. to a given
set of rules; the same inputs should always have the same outputs. Other
important parameters like hierarchies in legal entities, conversion rate of
various currencies, reporting thresholds and regulatory classification mappings
are externalized off code and governed by controlled configuration tables. This
separation of parameters and logic increases transparency and gives the ability
to make changes controlled without necessarily having to redevelop, whilst
maintaining a clear audit trail of changes over time. All aggregation logic (rule
definitions, dependencies order of execution, etc.) is described and reconciled
with regulatory interpretations and governing internal policy. Aggregation
logic is formalized in version managed repositories having formal change
management and approval procedures that support auditability and supervisory
review. The versions of the logic are marked to which reporting periods are
applied, which makes it possible to recreate historical submissions accurately
and provide remediation or re-calculation requests to regulators. Robots’ tests
checks confirm the results of aggregation with specified situations and
balances without any risks of undesirable effects being applied in response to
changes. The architecture enhances the integrity of data and regulatory
defensibility by imposing deterministic and parameterized aggregation. It sees
to it that the results of aggregation are clear, repeatable and to the point of
business semantics and regulatory definitions. This ability is especially vital
in resolution planning and stress testing, where regulators are interested in
being assured that reported numbers can be brought into play on the necessary
scrutiny and within limited timeframes.
3.5. Testing and validation matrix
The testing and
validation system is designed in a multi-dimensional matrix, which is aimed at
providing holistic assurance of the regulatory reporting pipeline. Instead of
using one testing stage, the architecture uses a number of various types of
tests which are aligned to various areas of risk and give the architecture
correctness in both technical and regulatory sense. This stratified methodology
helps in the early identification of defects, manageable change process and
provide the traceable proof of rigor in testing so as to provide internal
control and audit.

Figure 4: Testing and
validation Matrix.
- Unit Testing: Unit
testing is a technique used to test single transformation rules and
calculations and data enrichment logic. All the rules undergo testing on
pre-defined scenarios of inputs and outputs to ensure to conform to the
documented business and regulatory needs. Unit tests test that transformation
logic is working as desired, responds to edge cases in a reasonable manner and
gives consistent results given work with known conditions. This test layer
enables defects to be curtailed at an early stage before they can trickle down
to lower aggregation and reporting operations.
- Integration Testing: The integration testing ensures that there are end-to-end data
flows between various systems and architecture layers, including ingestion of
data sources, transformation and reconciliation on the data to regulatory
output. The aim is to verify that data interfaces, dependencies and sequencing
are as expected when interaction between components occurs within a
production-like setup. Tests which verify schema compatibility, reference data
joins as well as cross-domain consistency, ensure that the pipeline is made to
work as a cohesive unity and not as a collection of independent modules.
- Regression Testing: To achieve stability and consistency in regulatory outputs despite
system enhancements, regulatory code change or infrastructure improvement,
regression testing is conducted. Regression testing detects the unintentional
impacts of changes by performing regression testing of previously tested cases
and situation comparisons. This is especially critical in a regulatory setting
where any slight deviation can attract questions of supervision or formal
clarification.
- Scenario Testing: Scenario testing is a method used to test behavior of the reporting
pipeline under pressure or hypothetical conditions used in the resolution
planning. Such tests measure how the aggregation logic and assumptions respond
to highly unlikely but possible situations, e.g. entity separability or
liquidity stress. Scenario testing aids in confirming the ability of the
architecture to uphold the regulatory prospects of stability and futuresight
test.
- Parallel Runs: Parallel runs Parallel runs are
operations that run the new reporting pipeline and compare the results to the
legacy processes in several reporting cycles. Analysis and the explanation of
differences and subsequent resolution are conducted to make integrity in the
new architecture. This method offers empirical demonstration of equivalence or
betterment, which contributes to controlled shift and control endorsement of
new reporting system.
3.6. Submission timeline and controls
A timeline that
comprises formal control gates that are meant to ensure there is accuracy,
accountability and regulatory compliance is controlling the regulatory
submission process19,20. Each of the
milestones of the timeline depicts an essential validation point at which the
data quality and the reconciliation state, as well as the governance approvals,
are confirmed before the next step is successful. this is a formalized method
of imposing a disciplined approach throughout the reporting chain and offers a
distinct indicative thread of control and decision making to internal audit and
oversight. When T-10 (Data Freeze) the source data is officially locked out to
the reporting period. Such freeze makes it consistent by avoiding the
introduction of changes which can compromise reproducibility and
reconciliation. All the data added on this level are versioned and tagged to
the reporting period to create a consistent baseline on the downstream
processing. Any exception or post freeze-adjustments may be stringently
escalated and approved and the nature of the reporting dataset is not
compromised. At T-7 (Reconciliation Signoff) all embedded reconcilments
throughout the pipeline, source-to-ingestion, ingestion-to-transformation and
aggregation-to-output must be engaged and officially examined. Exceptional
absences are enquired, clarified or clearly explained within justified
boundaries of tolerance. Independent functions of control offer checks on
whether figures which are reported have been reconciled to sources of authority
and adhered to standard practices of internal controls. At T-3 (Management
Certification) the senior management examines the final regulatory outputs,
supporting documentation and control evidence. Management certification will
ensure that submissions are complete, accurate and prepared as per what a
regulatory expects of submissions. The action strengthens accountability on the
right level of the organization and integrates the reporting outcomes provided
on the governance and risk supervision functions. At T (Regulatory Submission),
the final reports and data files are technically presented into the hands of
the regulator via established channels. Approvals, submission artifacts and
timestamps are stored to allow auditability and post-submission inquiries. All
these gated controls result in a clear, repeatable and regulator-ready
submission process which can stand up to supervisory review.
4. Results and Discussion
4.1. Data quality improvements
Table 1: Data Quality
Improvements.
|
Metric |
Improvement
(%) |
|
Manual Adjustments |
65% |
|
Submission Cycle Time |
53% |
|
Regulator Queries |
50% |
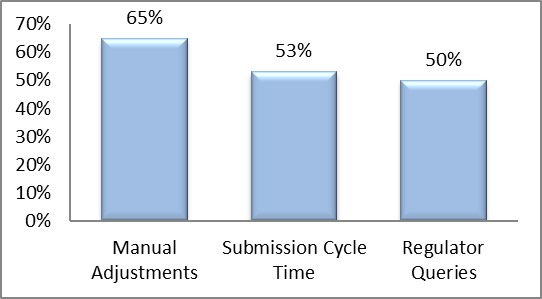
Figure 5: Graph
representing Data Quality Improvements.
- Manual adjustments (65% Improvement): The introduction of
the controlled, deterministic regulatory reporting architecture led to a huge number
of manual adjustments reduced. With the capability to build standardized
ingestion, controlled reference data, deterministic aggregation logic and
multi-layer reconciliations, a significant number of data anomalies that had to
be handled by people beforehand was removed on the fly. Robotic controls and
rule-based transformations minimized the use of spread sheets and hacks and
increased operational effectiveness and trust in the regulators. The fact that
the number of manual adjustments decreased 65 percent indicates a better degree
of data consistency, enhanced upstream data quality and greater execution of
control, on a reporting cycle.
- Submission cycle time (53% Improvement): By almost a half,
the time lag in submission cycles was selected to lessen, implying a decrease
in 15 days to 7 days per reporting interval. The reason behind this was the
fact that the data problems were earlier identified through embedded
reconciliations, the root-cause analysis was quicker due to end-to-end lineage
and less rework was required due to incorrectly fixed manually. The workflows
were streamlined, control gates were already preset and the financial, risk and
survived coordination across the finance, risk and treasury functions enhanced
the reporting speed. Reduced cycle times will increase the capability of the
institution to meet the shorter regulatory deadlines, especially stress or
resolution situations.
- Regulator queries (50% Improvement): Regulator questions
of data accuracy, consistency and explainability reduced by half post
implementation. Improved data lineage, version-controlled logic and extensive
documentation have allowed quicker and more accurate responses to supervisory
questions. Regulators could more easily use reported figures that have been
traced to authoritative sources and fewer follow-up clarification requests
would be necessary. Such a decrease suggests that transparency and
defensibility of submission regulatory reports are enhanced, which reinforces
supervisory trust and also reduces the currently experienced compliance levels
among reporting teams.
4.2. Audit and supervisory outcomes
Audited and
supervised reviews (after implementation) showed a significant level of
improvement in the transparency, reliability and defensibility of the
regulatory reporting process. Internal and external audit controls verified the
completeness of a full, end-to-end data lineage with the ability to report
figures that are traceable unambiguously back to source systems to ingestion
and transformation and aggregation through to ultimate regulatory reporting.
The metadata generated by the system, a version-controlled logic and a
timestamped control evidence helped to fill the void of the lineage
documentation and provided the ability to verify the correctness and integrity
of the reported information in a manner that is independent of manual
explanations or additional analyses. Better control efficacy was also observed
by the auditors in the purpose of the reporting lifecycle with references to
the areas of reconciliation, reference data governance and change management.
Buried reconciliations and explicit authorization processes minimized the
occurrence of undisclosed variance and the accurate recreation of submissions
in the past was achieved through good dating and versioning. Such possibilities
would help in mitigating the usual audit findings regarding data integrity,
inadequacy in documentation and inability to reproducely perform audits and
consequently reduce the amount of audit observations and re-mediation needs. As
a supervising aspect, regulators indicated an enhanced transparency and
effectiveness when it comes to examination and review. The standardization of
data definitions, deterministic aggregation logic and a rigorous lineage had
the important benefit of reducing the time needed to comprehend the reported
numbers and examine anomalies. Supervisory enquiries might be solved faster
because of the possibility to deliver uniform and well documented
clarifications with auditable support. This increased transparency boosted
confidence of regulators to the reporting system of the institution and ensured
that requests of data had to be repeated or follow-up reviews were lengthy. All
in all, the better audit and supervisory results indicate that the improved
efficiency of the operations is not accidental but, on the contrary, the
architecture contributes to the explainability, governance and control
regulatory expectations directly. This is especially essential in the context
of resolution planning, as regulators need to be extremely confident in the
capability of the institution to generate correct, prompt and justifiable data
when there is increased pressure and stricted deadlines.
4.3. Operational efficiency
The delivery of
automated reconciliation and deterministic aggregation logic has significantly
improved the productivity level of the operational aspects of the regulatory
reporting pipeline. The rule-based validations and systematic reconciliation
checks ensured on various levels, such as the source-to-ingestion,
ingestion-to-transformation and aggregation-to-output levels, helped to
decrease the number of steps that require manual work by subject-matter experts
to considerably. In the past, the complicated data problems and inconsistency
could easily involve intense scrutiny by finance, risk and treasury
professionals, leading to a point of congestion and resulting in an operational
risk associated with key-person dependency. The automatization and
standardization of processes are used to make sure that the tasks are performed
consistently, accurately and reproducibly and that fewer are utilized to these
processes, along with enhancing their overall resilience. Deterministic logic
also leads to efficiency in operative processes by eradicating discretionary
overrides and ad hoc calculations. All rules of transformation and aggregation
are parameterized, version-managed and well documented and the data may pass
through the pipeline without any manual reconfiguration. This does not only
increase the speed of the reporting cycle but also makes outputs predictable
and easy to audit. The architecture will eliminate the repetitive human effort
required and allow staff to work on activities associated with increased value,
including the analysis of exceptions, scenario planning and regulatory
engagement instead of daily data corrections or reconciliations. Combining
automated controls, embedded reconciliations and deterministic logic contribute
to lowering error propagation thus improving the reliability of upstream and
downstream processes. Reduced errors will lead to shortening of the cycle time,
average cut in regulatory inquiries and reworks, all of which can be tracked to
efficient gains. Also, the standardized processes enable scalability, so that
the institution can easily handle more and more volumes of data or more
regulation needs without corresponding staffing growth. All these operational
enhancements, in general, help the institution to make prompt, correct and
justifiable regulatory submissions and reduce the risks that come with
personnel dependency and manual processing. This leads to a more robust,
effective and sustainable reporting system that can respond to the changing
supervisory requirements and organizational expansion requirements.
5. Conclusion
The article posted
will describe a detailed, reconciled and traceable data pipeline system that
was dedicated to the FDIC resolution planning and high-frequency regulatory
reporting. The framework handles the key issues regarding contemporary
regulatory reporting, combining various levels of control, governance and
automation. Centralized reference data controls provide consistency, versioning
and an effective-dated reproducibility of important dimensions like the legal
entity, product hierarchy and counterparty classification. Multi-stage
dual-control reconciliations occurring between source-to-ingestion,
ingestion-to-transformation and aggregation-to-output confirm that the data
remains accurate and that anomalies are identified at an early age and supports
this information with auditing evidence to promote supervisor looking-glass
self-assurance. Deterministic aggregation logic is rule-based and
parameterized, version-controlled and documented and removes discretionary
overrides and produces reproducible results. In addition to these controls, a
formal testing and validating matrix, comprising of unit, integration,
regression, scenario and parallel testing is used, to ensure every part of the
pipeline is not only sound, but also reliable as well as in line with
regulatory expectations. Together, these contributions form a framework which
can produce audit ready, high quality regulatory information at scale and
shorten operational risk, cycle time and the use of subject-matter experts.
There is next
generation regulatory impact to the implementation of traceable and regularly
adjusted pipelines. With an ever-growing focus on transparency, reproducibility
and quick reaction to questioning on the part of supervisory authorities,
strong data pipelines are turning into a key part of the infrastructure, not a
superfluous improvement. The regulators are not only focusing on the accuracy
of the reported metrics but also on whether the institution can be able to show
full lineage including their ability to reconcile disparities and explain
variances as they arise in good time. Through adopting controlled,
deterministic and auditable reporting pipelines, institutions will be able to
address such increased expectations, increase the number of regulator queries
and enhance the trust in their reporting systems. Further, the architecture can
be used to ensure scalable compliance and to meet changing reporting
requirements, stress scenarios and resolution planning exercises without having
to make significant rework or draw on manual processes.
This framework can
be continued strategically in different ways in future research. The
incompatibility of reporting standards, legal entity structure and supervisory
expectations/ expectations across several regulatory regimes presents special
problems in cross-jurisdictional resolution planning and the framework would be
amenable to such complexities. Another frontier is real-time supervisory
reporting, potentially made possible by streams of data in high frequency and
automated controls that might permit near-instant reconciliation and submission
of regulations. Moreover, the adoption and adaptation with the new regulatory
technologies, including distributed ledgers, artificial intelligence-based
anomaly detectives and technological data provenance assistants, would
contribute to its transparency, predictive microeconomic efficiency and
capability. Considering these possibilities, the future of work might be
developed, basing on the basis of this paper, establishing regulation reporting
systems that are more robust, flexible and adapted to the changing environment
of the supervisory expectations.
6. References
- Supervision B. Basel committee on banking supervision.
Principles for Sound Liquidity Risk Management and Supervision, 2011.
- FSB. Key attributes of effective resolution regimes for
financial institutions, 2014.
- Bonollo M, Neri M. Data quality in banking: Regulatory
requirements and best practices. Journal of risk management in financial
institutions, 2012;5: 146-161.
- Khatri
V, Brown CV. Designing data governance. Communications of the ACM, 2010;53(1): 148-152.
- Otto B. Organizing data governance: Findings from the
telecommunications industry and consequences for large service providers.
Communications of the Association for Information Systems, 2011;29(1): 3.
- Buneman P, Khanna S, Wang-Chiew T. Why and where: A
characterization of data provenance. In International conference on database
theory, 2001: 316-330.
- Bovenzi JF. Inside the FDIC: Thirty years of bank failures,
bailouts and regulatory battles. John Wiley & Sons, 2015.
- Gordon M. Reconciliations: The forefront of regulatory
compliance procedures. Journal of Securities Operations & Custody, 2016;8: 356-363.
- Li J, Maiti A, Fei J. Features and scope of regulatory
technologies: challenges and opportunities with industrial internet of things.
Future Internet, 2023;15: 256.
- Bhatt T, Cusack C, Dent B, et al. Project to develop an
interoperable seafood traceability technology architecture: issues brief.
Comprehensive Reviews in Food Science and Food Safety, 2016;15: 392-429.
- Leuz C. Different approaches to corporate reporting
regulation: How jurisdictions differ and why. Accounting and business research,
2010;40: 229-256.
- Bowen F, Panagiotopoulos P. Regulatory roles and functions
in information-based regulation: A systematic review. International Review of
Administrative Sciences, 2020;86: 203-221.
- Marchini PL andrei P, Medioli A. Related party transactions
disclosure and procedures: a critical analysis in business groups. Corporate
Governance: The International Journal of Business in Society, 2019;19: 1253-1273.
- Kraakman RH, Armour J. The anatomy of corporate law: A
comparative and functional approach. Oxford university press, 2017.
- Bennett M. An industry ontology for risk data aggregation
reporting. Journal of Securities Operations & Custody, 2016;8: 132-145.
- Cai S, Gallina B, Nyström D, et al. Data aggregation
processes: a survey, a taxonomy and design guidelines. Computing, 2019;101: 1397-1429.
- Fang Z. System-of-systems architecture selection: A survey
of issues, methods and opportunities. IEEE Systems Journal, 2021;16: 4768-4779.
- Mahoney W, Gandhi RA. An
integrated framework for control system simulation and regulatory compliance
monitoring. International Journal of Critical Infrastructure Protection, 2011;4:
41-53.
- Bamberger KA. Technologies of compliance: Risk and regulation in a digital age. Tex L Rev, 2009;88: 669.
- Sparrow MK. The regulatory
craft: controlling risks, solving problems and managing compliance. Bloomsbury
Publishing USA, 2011.