Infrastructure Improvements Execution Plan: A Technical Analysis of Key Decisions in Data Management and Machine Learning Operations
1.
Abstract
In
the rapidly evolving landscape of data science and machine learning, the
infrastructure that underpins these technologies plays a pivotal role in the
success of projects and operations. This paper delves into the essential
components and strategic decisions in developing an advanced infrastructure
tailored for data management and ML operations. By examining key areas such as
version control, continuous integration and deployment, cloud computing
platforms, interactive computing environments, and micro services architecture,
we aim to outline a comprehensive execution plan. The insights guided the
optimization of the infrastructure to support scalable, efficient, and secure
data and ML workflows, drawing from various sources, including foundational
texts and cutting-edge practices.
2. Keywords: Machine Learning Operations (MLOps), Continuous Integration/Continuous Deployment (CI/CD), Git, AWS MWAA, AWS Sagemaker
3. Introduction
The technological landscape for software development and data science has undergone transformative changes, significantly influenced by advancements in version control, continuous integration, cloud computing, interactive computing environments, and micro services architecture. Exploration of version control with Git underscores the importance of collaborative tools in the software development life cycle, enabling teams to manage changes and collaborate more effectively. This foundational approach highlights the role of automated testing and integration in maintaining software quality and reducing deployment risks.
The shift towards cloud computing represents a paradigm shift in utilizing resources, offering scalable and flexible infrastructure solutions that are pivotal in data science and ML operations. Jupyter Notebook enriches this cloud-based approach, emphasizing the interactive computing environment's value in facilitating exploratory data analysis and machine learning model development.
Introducing the concept of micro
services and the practicalities of building data science on cloud platforms
provide a comprehensive overview of the best practices and patterns
for designing micro services that support modular,
scalable applications and the intricacies of leveraging cloud infrastructure for data science
projects.
This paper aims to synthesize these foundational concepts and practices into a coherent execution plan for infrastructure improvements, focusing on data management and machine learning operations. By critically analyzing the interplay between these technological advancements, we propose a roadmap for developing an advanced infrastructure that supports the increasingly complex requirements of modern data science and machine learning projects.
4. Key Area of Focus
Tools like Git significantly enhances collaboration and data/code management in machine learning
(ML) projects by providing a robust
framework for version control. Git allows multiple developers to work on the same project simultaneously, enabling efficient tracking
of changes, resolving conflicts, and ensuring
consistency across different project versions.
This streamlined approach
to managing project
iterations facilitates faster development cycles,
improves code quality,
and accelerates the deployment of reliable ML models, thereby
fostering a collaborative environment that drives
innovation and productivity in the development of ML applications1
(Figure 1).

Figure
1: The centralized and distributed paradigms2.
Continuous Integration (CI) and Continuous Deployment (CD) practices
are pivotal in automating the testing and deployment
of machine learning (ML) models. They establish a systematic and automated way to build, test, and deploy ML models,
ensuring that new code changes
are integrated seamlessly and that ML models are
consistently updated and deployed
without manual intervention. This process mitigates the risk associated with manual deployments and significantly enhances software quality by facilitating
frequent and reliable code updates3.

Figure 2: A CI/CD diagram4.
Leveraging cloud services such as AWS provides scalable data storage, processing, and machine learning (ML) model training solutions. AWS offers a broad array of services that enable efficient handling of large datasets, facilitate complex computational tasks, and streamline the development and deployment of ML models. This approach enhances the flexibility and scalability of ML projects. It optimizes resource utilization, allowing organizations to focus on innovation and achieve significant computational power without requiring extensive hardware investments (Figure 2).
Platforms like Jupyter Notebooks play a pivotal role in data science by significantly enhancing data exploration and model development and facilitating collaboration among data science teams. These interactive computing environments offer an intuitive interface for writing and executing code, visualizing data, and sharing insights. This seamless integration of code, visual output, and narrative documentation within a single notebook fosters a collaborative atmosphere, enabling teams to work more efficiently and transparently. Consequently, Jupyter Notebooks have become indispensable tools in the data science workflow, promoting innovation and accelerating project development.
Microservices patterns offer a strategic approach to building flexible and scalable machine learning (ML) applications, allowing for the modular development of services that can operate and scale independently. This architectural style supports the rapid, reliable delivery of complex, large-scale ML systems, enhancing agility and enabling continuous integration and deployment practices. By adopting microservices, developers can isolate and address specific domains within ML projects, facilitating easier updates, faster deployment cycles, and more robust scalability options, which are crucial for adapting to the evolving needs of data-driven organizations.
Constructing a data science framework on Amazon Web Services (AWS) involves leveraging its extensive suite of cloud computing services to manage data processing, analysis, and machine learning operations efficiently. This strategy encompasses utilizing AWS's storage solutions for scalable data warehousing, employing compute services for powerful data processing, and leveraging machine learning services for model training and deployment. AWS facilitates seamless integration of these components, enabling data scientists to focus on extracting insights and building models rather than managing infrastructure. With AWS, teams can scale their data science capabilities flexibly, ensuring that resources are optimally allocated to meet the demands of complex analytics projects5.
5.
Methodology
Our methodology for enhancing the infrastructure was meticulously
designed and executed, incorporating advanced
technologies and strategic processes to address the specific needs of our data management and machine learning
operations.
Initially,
we adopted Git & GitHub as our version control system. Our extensive
testing confirmed Git's superior branching and versioning capabilities
compared to SVN. The distributed nature of
Git, as opposed to SVN’s centralized repository
system, provided the flexibility and risk reduction needed for our CICD workflows, confirming its suitability (Figure
3).

Figure 3: End-to-end machine learning pipeline6.
Implementing GitHub Actions for CICD enhanced
our software development process. Our practical
trials demonstrated GitHub's
effectiveness in creating an integrated, cloud-based environment, simplifying and
streamlining our CICD pipeline. This
setup was instrumental in improving our deployment
frequency and reducing the time to deployment.
We integrated AWS SageMaker to manage ML models, following
insights. Our experiments and trials with SageMaker indicated
that its fully managed services
significantly reduced our team's
infrastructure management overhead. SageMaker
balanced manageability and customizability, crucial
for efficiently deploying
machine learning models (Figure 4).
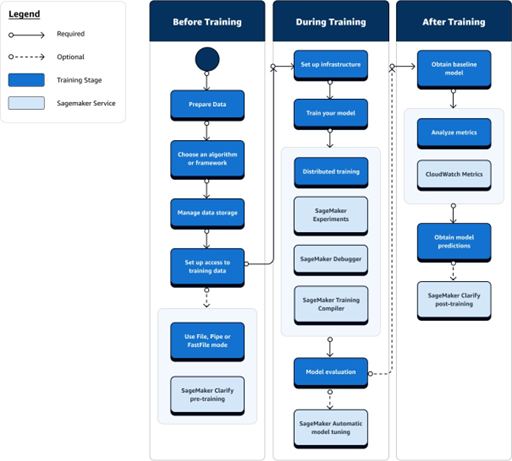
Figure 4: AWS SageMaker Training workflow7.
We utilized Jupyter Notebooks for data analysis. Our comparative analysis with AWS SageMaker development endpoints underscored its cost-effectiveness and ease of setup for exploratory data analysis, making it a practical choice for our data scientists.
We experienced enhanced flexibility and efficiency by adopting a micro services architecture. Our implementation of Git submodules for managing these micro services effectively balanced the benefits of a micro services architecture with the cohesiveness of a monolithic approach. This architecture proved instrumental in facilitating independent development and testing of services while maintaining overall system integrity.
Choosing AWS MWAA for managing ETL services streamlined our data processing workflows. Our testing
showed that AWS MWAA's scalability and robustness made it a superior choice over alternatives like AWS Glue and self-managed solutions, aligning with the industry’s trend towards managed
cloud services. Lastly,
we created standardized template repositories for various pipeline
segments7. Our trials and
applications of these templates demonstrated their effectiveness in ensuring operational consistency and efficiency in ML workflows. This standardization
approach simplified the process of setting up
new ML projects, significantly reducing the time and effort required
for initial configuration (Figure
5).

Figure
5: Amazon MWAA Architecture8
These methodological decisions were backed by extensive testing, practical trials, and comparative analyses, ensuring they were theoretically sound and practically reasonable in our organizational context.
6.
Conclusion
Our
application of these methodologies led to significant improvements in our infrastructure. The adoption of Git & GitHub enhanced our version control
processes, while GitHub Actions
streamlined our CICD pipelines. SageMaker proved invaluable in managing ML models, and Jupyter Notebooks was highly effective
for exploratory data analysis. The micro
services architecture, coupled
with Git submodules, offered flexibility and efficiency in development. AWS MWAA enhanced
our ETL services, and the standardized template repositories for pipeline segments
established a consistent and efficient approach
to ML operations.
Our application of these methodologies led to significant improvements in our infrastructure. The adoption of Git & GitHub enhanced our version control processes, while GitHub Actions streamlined our CICD pipelines. SageMaker proved invaluable in managing ML models, and Jupyter Notebooks was highly effective for exploratory data analysis. The micro services architecture, coupled with Git submodules, offered flexibility and efficiency in development. AWS MWAA enhanced our ETL services, and the standardized template repositories for pipeline segments established a consistent and efficient approach to ML operations.
Our infrastructure improvement plan's strategic decisions and methodologies have demonstrated their effectiveness in enhancing our data management and machine learning operations. Integrating modern tools and approaches grounded in scholarly research and industry best practices has resulted in a more efficient, scalable, and reliable system. Our experiences underline the importance of adapting to emerging technologies and methodologies in the rapidly evolving data and ML operations landscape.
The critical insights from the analysis underscore the pivotal role of strategic planning and the implementation of best practices in enhancing infrastructure for data management and ML operations. Key areas such as version control, CI/CD, cloud computing, interactive environments, and micro services architecture demand careful consideration. Success hinges on integrating these components cohesively, ensuring scalability, efficiency, and collaboration. Adopting these strategies enables organizations to navigate the complexities of modern data science and ML landscapes effectively, paving the way for innovation and competitive advantage in a rapidly evolving digital world.
7. References
- Loeliger J,
McCullough M. Version control with Git: Powerful
tools and techniques for collaborative software development. O'Reilly Media, 2012.
- Codoban M. A
comparative study on how SVN and Git affect software
changes. Oregon State University, 2015.
- Duvall PM,
Matyas S, Glover A. Continuous Integration: Improving software quality and reducing risk.
Addison-Wesley, 2017.
- Posoldova A. Machine Learning Pipelines: From Research to Production. IEEE Potentials, 2020;39;
38-42.
- Wittig A,
Wittig M. Amazon Web Services in Action. Manning
Publications, 2018.
- Vadavalasa RM. End to end CI/CD pipeline for Machine Learning. International Journal of Advance Research, Ideas and Innovation in Technology, 2020;6: 906-913.
- Amazon, Train machine
learning models. Amazon, 2023.