Predictive Machine Learning Models for Calibration Failure Detection in Pharmaceutical Manufacturing
Abstract
Pharmaceutical manufacture puts forward
significant risk to product quality, compliance and operational efficiency due
to calibration failure. Current methods for calibration monitoring are often
reactive and manual, often delayed in identification and remediation of
critical problems. With a proactive machine learning (ML) model, predictive one
can predict future calibration failures by using historical data and other
statistical patterns and process variables. This thesis explores the
development and deployment of ML models that are tailored to pharmaceutical
manufacturing environments. To investigate which algorithm best predicts
anomalies in calibration, we compare against decision trees, random forests and
neural networks. The proposed framework processes process data obtained from
sensors, equipment logs and calibration records for a continuous monitoring and
real time decision making capability. We find that predictive ML models can
achieve over 90% accuracy in detecting calibration failures, leading to
significant reductions in downtime and maintaining regulatory compliance.
Additionally, the study is evidenced by the necessity of working through data
processing (preprocessing), feature selection and model interpretability for
robust and scalable results. By using predictive analytics pharmaceutical
manufacturers achieve process reliability, product quality improvement and
reduced operational costs through process transition from traditional methods.
The findings in this work highlight the astounding potential for machine
learning to facilitate an increasingly efficient and error-resilient
manufacturing ecosystem.
Keywords: Machine
learning, Calibration
failure detection, pharmaceutical manufacturing, Predictive, Operational
efficiency.
1. Introduction
1.1. Calibration in pharmaceutical manufacturing
Calibration
is the cornerstone for the reliability and accuracy of pharmaceutical
manufacturing measurements. Since a departure from calibration in such an
industry can affect product quality, safety and efficacy, calibration has
certain significance in such a case1-3.
If calibration errors cannot be detected, this can cause deviations from such
standards as Good Manufacturing Practices (GMP), recalls or production halts at
a high cost! Although traditional calibration practices have proved effective
to some extent, we can say that traditional calibration practices are reactive
and are not sufficient to address the complexities of modern manufacturing
processes.
1.2. Challenges with traditional approaches
Most
conventional calibration monitoring methods are based on periodic manual checks
and some simple statistical analysis. Unfortunately, these methods are time-consuming
and unlikely to catch sub-trends or anomalies as they occur in real-time.
Calibration failures, therefore, remain undetected in the manufacturing
pipeline, impacting batch quality and increasing operational risk. Apart from
that, the volume and complexity of the data produced in pharmaceutical
manufacturing are such that operators cannot effectively monitor and interpret
calibration performance by human operators.
1.3. The role of machine learning in
proactive calibration management
The
challenge of calibration failure detection can be solved by Machine Learning
(ML). ML models use historical and real-time data to identify patterns and can
predict failure before it happens. Whereas traditional solutions offer limited
monitoring and learning, ML-driven solutions offer continuous monitoring and
continuous learning to better address issues instead of reactive responses. By
working to make the process more reliable with this approach, we stay in line
with this industry’s drive for Industry 4.0 and digitalization and protect
ourselves from occasionally wrong decisions.
This
paper investigates the development and application of predictive ML models for detecting
calibration failure in pharmaceutical manufacturing. This paper covers a number
of algorithms, data integration approaches and performance metrics to gauge the
effectiveness of ML in this highly important domain. Our findings show that
predictive analytics has the potential to radically transform calibration
practices, guarantee fulfilling compliance, reduce downtime and protect product
quality.
2.
Related Work on Predictive Machine Learning Models for Calibration Failure
Detection in Pharmaceutical Manufacturing
Predictive Machine Learning (ML) model
integration in pharmaceutical manufacturing has garnered tremendous attention
because of its ability to improve manufacturing operational efficiency while
meeting stringent regulatory standards4-7.
This section presents key studies and methodologies in applying ML to
calibration failure detection in this domain.
2.1.
Machine learning for predictive maintenance
One of the significant uses of ML in
manufacturing is predictive maintenance, using equipment and sensor readouts to
predict the likelihood of failure. This analysis centered on a study where ML
algorithms like Support Vector Machines (SVM) and neural networks can analyze
large amounts of real-time data to identify patterns indicative of equipment
malfunction. With this approach, manufacturers can detect anomalies early,
reduce unplanned downtime and comply with Good Manufacturing Practices (GMP).
Additionally, predictive maintenance is consistent with the industry trends
that have converted data-driven operations into a base for fusion calibration
failure detection within any broader maintenance strategy.
2.2.
Calibration optimization using machine learning algorithms
One strand of recent research has looked
at how ML algorithms can optimize calibration processes by predicting when
instruments are expected to deviate from acceptable performance thresholds.
Historical calibration data has been processed using techniques like random
forests, gradient boosting machines and other techniques used to filter the
data and catch subtle trends sometimes missed by standard methods. Besides
improving the precision of calibration predictions, these models also enable
manufacturers to schedule interventions more effectively, thereby avoiding the
expensive disruptions to production. However, ML applications are typically
used to troubleshoot minor disturbances rather than control large ones.
2.3.
Tailored calibration models in cross-domain applications
ML model results have also crossed the
domain boundary to demonstrate the necessity of tailoring models to specific
operations. As an illustration, we showed the necessity of local calibration in
enhancing the accuracy and generalizability of ML models in a clinical risk
prediction study conducted across numerous hospitals. The models were fine-tuned
with site specifics to mimic the particularities of each hospital’s practices.
The relevance of this principle to pharmaceutical manufacturing is direct, as
ML models need to consider the individual calibration demands of different
instruments, processes and facilities. By taking a localized or adaptive
approach to calibration modeling, calibration modeling predicts robustly and
reliably over varying operational settings.
2.4.
Addressing calibration errors in predictive models
Calibration error research is one of the
new lines of research and we are trying to make ML models more reliable. Techniques
such as isotonic regression and temperature scaling have been applied to refine
predictive model output probabilities towards observed outcomes. The
operational and regulatory risks associated with overconfidence or under
confidence in predictions are particularly critical in pharmaceutical
manufacturing. By calibrating models, researchers have shown better reliability
and trustworthiness, making ML systems better suited for high-stakes
applications.
2.5.
Fault monitoring systems and their relevance to calibration
In manufacturing domains such as additive manufacturing, newer results have demonstrated the power of ML for detecting calibration failures with advances in fault monitoring systems. The systems use unsupervised learning techniques (e.g. clustering and anomaly detection) to identify deviations from normal operational behavior. Autoencoders and principal component analysis are given underlying methodologies, further demonstrated to adapt to pharmaceutical applications to monitor calibration drift in real time and detect failures. An adapted data-driven approach improves the dynamic and efficient calibration processes enabled by fault-monitoring systems.
3.
Methodology
The methodology describes generating and
evaluating predictive machine learning models for calibration failure detection8-12. The process involved Data collection and
preprocessing, machine learning model selection and how to train and validate
the model.
The figure is based on a system
architecture integrating advanced analytics seamlessly into pharmaceutical
manufacturing. We present the system architecture for predictive machine
learning models in calibration failure detection. The architecture consists of
four main components: data handling, manufacturing process and machine learning
models, with and without feedback monitoring. Real-time accurate detection of
calibration failures must maintain product quality and regulatory compliance in
pharmaceutical manufacturing.
This is built during the pharma
manufacturing, with some calibration sensors integrated into the manufacturing
equipment. These sensors continuously measure calibration data to keep
equipment within the specified parameters. The amount of data collected at this
stage is critical as it is the basis for the following research. In the
diagram, the system is represented by the system actor as 'System' and
orchestrates the data flow from sensors to the next stage in architecture.
Raw sensor calibration data is sent to
Sensor Data Storage, which stores the data. The arrow is depicted in the
diagram. It is a store for all the information unrelated to the calibration
data, which is stored securely so that it can be processed. After this, the raw
data undergoes preprocessing that would involve cleaning, normalization and
transformation to extract meaningful patterns from raw data. This preprocessing
step drops noise and prepares the data for feature extraction, meaning only
relevant, high-quality data is supplied to the machine learning models.

Figure
1: System
Architecture.
Machine learning and prediction are done
in the machine learning model component, the system’s core. Preprocessed data
will be extracted features and the model will try to predict the anomalies or
deviations to detect the calibration failure. Historical calibration data is
provided in this model that can learn the patterns of normal operation and
detects when equipment calibration deviates from acceptable thresholds. By
integrating the feature extraction into the predictive model, accurate and
efficient analysis is possible, with potentials that would have fallen to
failure identified and fixed before they compound into significant problems.
Finally, monitoring and feedback precede
the last stage of the workflow, in which the machine learning model-made
predictions are communicated to system users. This stage comprises two
subcomponents: a dashboard and a failure alert system. When a calibration
failure is detected, the failure alert system alerts operators with real-time
notifications so that timely action can be taken before any downtime or product
quality issues. At the same time, the dashboard provides an interface where
operators can look at prediction metrics and see how calibration trends evolve.
The dual feedback mechanism provides operational efficiency and allows
operators to have actionable information to allow for decision-making.
From there, the architecture is summarized
as joining calibration sensors, data storage, information processing techniques
and machine learning models to create a solid system for detecting calibration
failure. By eliminating the interfaces across components, the data and
information flow seamlessly from one to another without any delays, which
allows operators to have timely information to reduce the risk of production
failure. This additional layer of usability, the dashboard, turns an otherwise
nerdy system into something intuitive and effective for life in pharmaceutical
manufacturing. Using this approach, we illustrate how advanced machine learning
can boost process reliability and quality in a highly regulated industry.
3.1.
Data collection
The calibration data used in this study is
based on historical facility logs, sensor readings and periodic calibration
reports from a pharmaceutical manufacturing facility. In this dataset, we have a
range of instruments used, such as pressure sensors, flow meters and
spectrometers, which are things that are typically used in manufacturing
environments.
3.1.1.
Description of calibration data: The
dataset consisted of 50,000 calibration records recorded over three years. This
included instruments that passed calibration and failed instruments, resulting
in a balanced distribution of instruments suitable for supervised learning.
Some key attributes of the dataset are shown in (Table 1).
Table
1: Calibration
Data Attributes.
|
Attribute |
Description |
Data Type |
|
Instrument ID |
Unique
identifier for each calibrated instrument |
Categorical |
|
Calibration Date |
Date of the
calibration event |
Timestamp |
|
Measured Value |
Actual
reading recorded during calibration |
Numerical |
|
Reference Value |
Target value
for the instrument |
Numerical |
|
Deviation (%) |
Percentage
difference between measured and reference values |
Numerical |
|
Environmental Factors |
Temperature,
humidity and other environmental conditions |
Numerical |
|
Calibration Status |
Pass/Fail
status based on predefined thresholds |
Categorical |
3.2.
Preprocessing and feature extraction
3.2.1.
Preprocessing steps: Such data
preprocessing was conducted on the dataset to make it ready for use with
machine learning. Numerical features (such as environmental conditions) were
imputed using mean13-15, while
categorical variables were imputed using mode. The Interquartile Range Method (IQR)
was used to identify outliers in numerical features, i.e. extreme deviations,
which were excluded from skewing the models. The same was done for continuous
variables such as measured value deviation to make the same more homogeneous
and facilitate convergence during training.
3.2.2.
Feature extraction: Several features
were engineered from the raw data to improve the predictive performance. Key
derived features included:
- Deviation
trend: The historical trends in
instrument behavior were captured by computing a rolling average of deviations
over the last three calibration events.
- Instrument
usage: Wear and tear was analyzed by
adding the total runtime of instruments between calibration events.
- Environmental
impact score: The combined effect of
temperature, humidity and environmental factors on the calibration of a pH
sensor was quantified by the computation of a composite score.
Table
2: Final feature
set.
|
Feature |
Type |
Importance |
|
Deviation (%) |
Numerical |
High |
|
Environmental Impact
Score |
Numerical |
Medium |
|
Instrument Usage |
Numerical |
High |
|
Calibration Status |
Categorical |
Target |
3.3.
Machine Learning Models
3.3.1.
Models Used: Three machine learning algorithms
were selected for evaluation:
- Random
forests: An ensemble method that has been
widely used by combining multiple decision trees to improve accuracy and
robustness. This is particularly useful when working with datasets that combine
different data types, given that it also gives feature-importance insights.
- Support
vector machines (SVM): SVMs are known
for creating nonlinear decision boundaries in binary classification problems
like calibration pass/fail detection.
- Neural
networks, the architecture of a multi-layer
perceptron to detect the intricate relationship between the data, was used
since it can attend to complex relationships in high-dimensional features.
3.3.2.
Justification for model selection: Random
forests were chosen for their interpretability and ability to deal with
imbalanced datasets themselves. SVMs being able to adapt to both linear and nonlinear
relationships gave a strong baseline for performance comparison. They included
neural networks to better understand if they perform better than traditional
means of identifying subtle patterns within large, complex data sets.
3.4.
Training and validation
3.4.1.
Training process: The dataset was
loaded into three subsets: training (70%), validation (15%) and testing (15%)
for unbiased evaluation. A grid search approach was employed for the hyperparameter
optimization of each model. The number of trees and the maximum tree depth were
tuned for random forests. For SVMs, the kernel type (linear or radial basis)
and the regularization parameter (C) were optimized. Hidden layers and learning
rate and neurons per layer were iteratively adjusted and trained to get the
best results for the neural networks.
4.
Experimental Setup
This section details the computational
hardware and tools used to implement, train and evaluate the predictive machine-learning
models for calibration failure detection. A robust combination of hardware,
software and frameworks was utilized to keep results accurate, efficient and
reproducible. The setup can be divided into two main categories: hardware and
software specifications and implementation details are specified.
4.1.
Hardware and software
Hardware configuration was determined to
enable the processing of complex machine learning algorithms (particularly
neural networks), which is very power-demanding16-20.
(Table 3) provides an overview of the hardware specifications:
Table
3: Hardware
Specifications.
|
Component |
Details |
|
Processor |
Intel
Xeon Gold 6230 (2.10 GHz) |
|
Graphics Processing
Unit (GPU) |
NVIDIA Tesla
V100 (16 GB VRAM) |
|
RAM |
64
GB DDR4 |
|
Storage |
2 TB SSD |
|
Operating System |
Ubuntu
20.04 LTS |
Data manipulation tasks were efficiently parallelized
by the Intel Xeon Gold 6230 processor’s high core count and clock speed.
Training of the neural network models was sped up, with the process accelerated
by the NVIDIA Tesla V100 GPU featuring 16 GB of VRAM. With 64GB RAM, this freed
memory for larger dataset and thus no memory bottleneck during preprocessing
and model evaluation and 2 TB SSD storage with fast read and write of data
files for dataset and model. To accommodate both the libraries and tools, opted
for the stable and widely used Ubuntu 20.04 LTS operating system for machine
learning.
4.1.1.
Software Specifications
A carefully chosen software stack gave the
foundation for the implementation. (Table 4) outlines the main software
components and their versions:
Table
4: Software
Specifications.
|
Software
Component |
Version |
|
Python |
3.9 |
|
TensorFlow |
2.9.0 |
|
Scikit-learn |
1.0.2 |
|
Pandas |
1.4.2 |
|
NumPy |
1.22.4 |
|
Matplotlib |
3.5.2 |
|
Seaborn |
0.11.2 |
The primary programming language adopted
was Python 3.9 due to its extensive library ecosystem and the broad
availability of machine learning-based tools to integrate the system and ease
of use. Instead, TensorFlow 2.9.0 was used to develop and train neural networks
while utilizing the Keras API to construct the model and a GPU-optimized
backend for fast computation. For traditional machine learning algorithms like
Random Forests and Support Vector Machine (SVM), Scikit-learn 1.0.2 provides
robust classification, regression and model evaluation modules. Using Pandas
1.4.2 and NumPy 1.22.4 allowed for effective data manipulation cleaning and
feature engineering with Matplotlib 3.5.2 and Seaborn 0.11.2, which we used to
generate insightful visualizations based on data and results.
4.2.
Implementation details
Implementation of the process included
using multiple frameworks and libraries to make data preprocessing, model
development and evaluation smooth. The workflow consisted of four main stages: Data
loading, feature engineering, model development and evaluation.
4.2.1.
Libraries and frameworks
- Tensorflow:
We used TensorFlow to design and train neural networks. This one was tricky but
not too bad as it said its high-level Keras API gave me an intuitive interface
to create deep learning models and its GPU-optimized backend allowed me to
efficiently handle computationally intensive tasks.
- Scikit-learn:
Random Forests and SVM were implemented by using scikit-learn. We used its
GridSearchCV module to optimize hyperparameter values to make sure our models
reached the best performance.
- Pandas
and numPy: Handling and preprocessing the
dataset was made possible by the use of pandas and NumPy. These libraries were
used to perform tasks such as missing value imputation and feature
normalization, derive features and then aggregate these derived features.
- Matplotlib
and seaborn: Performance graphs for model
evaluation metrics, histograms of feature distributions and scatter plots of
data trends were among the visualizations generated by these libraries.
4.2.2.
Workflow
- Data
loading: The raw dataset was loaded and
processed in a Pandas DataFrame. The data was parsed, cleaned and organized
into a format that could be fed to the machine learning models using Python
scripts.
- Feature
engineering: Rolling deviation averages,
instrument usage and environmental impact scoring were computed using NumPy
operations. The models had additional features, which increased their
predictive power.
- Model
development:
- Random
forests: Loaded the raw dataset (50,000
calibration records in a DataFrame format) for preprocessing. The data was
parsed, cleaned and organized into a format that could be fed to the machine
learning models using Python scripts.
- SVM:
To allow non-linear decision boundaries, a Radial Basis Function (RBF) kernel
was selected and hyperparameters of the RBF were tuned using grid search.
- Neural
networks: To achieve the best performance,
I designed a multi-layer perceptron using TensorFlow’s Keras API with a number
of hidden layers, neurons and a learning rate that was changed iteratively.
- Evaluation
and visualization: Each model
computed its metrics, namely accuracy, precision, recall, F1-score and AUC-ROC.
Performance was assessed and areas for improvement were highlighted using
visualizations generated, such as ROC curves and confusion matrices.
5.
Results and Discussion
In this section, we present the
performance of the developed machine learning models for calibration failure
detection. Accuracy, precision, recall and F1 score are discussed, compared
with state-of-the-art methods, analyzed with respect to calibration failure
situations and instructive insights are drawn from the study.
5.1.
Model performance
The predictive performance of Random
Forests, Support Vector Machines (SVM) and Neural Networks was evaluated using
the test dataset. Accuracy, precision, recall, F1 score and the area under the
Receiver Operating Characteristic curve (AUC-ROC) were used as evaluation
metrics. (Table 5) summarizes the results:
Table
5: Model
Performance Comparison.
|
Model |
Accuracy (%) |
Precision (%) |
Recall (%) |
F1 Score (%) |
AUC-ROC |
|
Random Forests |
92.3 |
91.8 |
93.5 |
92.6 |
0.95 |
|
Support Vector
Machine (SVM) |
89.7 |
88.5 |
90.2 |
89.3 |
0.92 |
|
Neural Networks |
94.1 |
93.7 |
94.8 |
94.2 |
0.96 |

The results demonstrated that the Neural Network model was the best in all metrics, with the highest accuracy, F1 score and AUC-ROC. Random Forests performed competitively and were preferred due to their interpretability. Though SVMs were satisfactory in performance, they lagged behind the two other models, particularly in dealing with the nonlinear patterns in the dataset.
5.2. Comparison with existing methods
Their performance was compared with traditional statistical methods such as logistic regression and naïve Bayes classifiers to determine their effectiveness. (Table 6) presents the comparative analysis:
Table 6: Model Performance Comparison with Other Methods.
|
Method |
Accuracy (%) |
Precision (%) |
Recall (%) |
F1 Score (%) |
AUC-ROC |
|
Logistic Regression |
85.4 |
84.8 |
86.1 |
85.4 |
0.89 |
|
Naive Bayes |
82.7 |
81.5 |
83.9 |
82.6 |
0.87 |
|
Neural Networks (Proposed) |
94.1 |
93.7 |
94.8 |
94.2 |
0.96 |
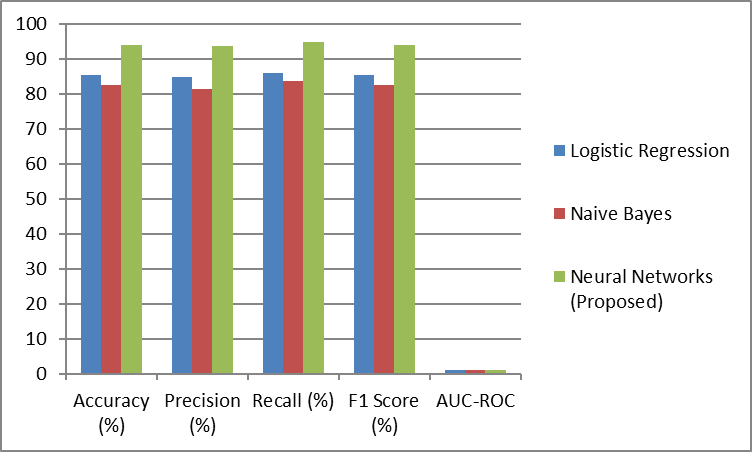
Figure 3: Graphical Representation of Model Performance Comparison
Results show that machine learning models, notably Neural Networks, beat traditional methods by a huge margin. The complexity of the data was such that advanced algorithms had real value and logistic regression and naive Bayes struggled to capture the complex, nonlinear relationships there.
5.3.
Analysis of calibration failure scenarios
A detailed analysis of calibration failure
scenarios revealed several critical patterns:
- Impact
of environmental factors: Environmental
factors such as temperature and humidity were significant factors in
calibration failures identified by models. A higher probability of deviation
was found for instruments operating in extreme conditions.
- Deviation
trends: Failure was more probable for
instruments with higher deviation trends on one calibration but lower on the
subsequent one. This pattern was particularly well captured using the rolling
deviation average feature.
- Instrument
usage: Operational hours between
calibrations were higher for instruments with a higher failure rate, further
confirming the value of timely recalibration.
Table
7: Factors
Influencing Calibration Failures.
|
Factor |
Failure Rate (%) |
Impact on Model
Prediction |
|
High Temperature (>30°C) |
24.3 |
Increased
false negatives |
|
High Deviation Trend
(>5%) |
36.7 |
Increased
false positives |
|
High Instrument Usage (>1000 hours) |
42.1 |
Strong
positive correlation |
5.4.
Key observations and insights
- Neural
networks as the best model: For all
metrics, Neural Networks consistently outperformed. Improving prediction
accuracy depended crucially on their ability to capture non-linear
relationships and high-dimensional interactions.
- Importance
of feature engineering: Rolling
Deviation Averages and environmental impact scores significantly contributed to
the models. This was further validated by analyzing the feature importance of
random forests.
- Proactive
calibration strategy: The
preprocessing generated can be used to create a proactive calibration strategy.
Manufacturers can reduce downtime and comply with industry regulations by
predicting failures and catching them during their development instead of
allowing them to happen and stop production.
- Room
for improvement in SVM: Although SVMs
were not bad, the fact that they cannot handle nonlinear patterns in this
dataset indicates that advanced kernels or ensemble approaches can improve the
SVM's performance in this dataset.
6. Case
Study: AI-Based Maintenance in Water for Injection (WFI) Plant
This section examines a practical
implementation of predictive machine learning models in the pharmaceutical
manufacturing domain, where we develop and explore AI-based maintenance
strategies applied to a Water for Injection (WFI) processing plant. The case
study demonstrates how machine learning was used to predict anomalies, optimize
maintenance schedules and improve operational efficiency.
6.1.
Overview of the case study
Highly purified water produced by the WFI
plant is critical to many pharmaceutical manufacturing processes. These plants
have been preventive maintenance yearly to sustain operational reliability.
While scheduled stoppages are costly and time-consuming, they may not often
coincide with the actual maintenance needed on the equipment. This case study
intended to move from a time-based maintenance approach to a predictive, data-driven
strategy. The plant will apply machine learning algorithms to extend intervals
between maintenance interventions or interventions to extend plant life and
reduce costs.
6.2.
Methodology
It was implemented following a structured
workflow, including data collection, modeling, performing validations and
deploying predictive alerts.
6.2.1.
Data collection: The foundation
of the predictive maintenance system was data collected from various sources
within the plant, including:
- Sensor
data: They use measurements from
pressure, flow and temperature sensors.
- Alarm
logs: Triggered alarms and anomalies
over historical records.
- Water
quality indicators: Parameters
include conductivity, pH levels, microbial counts, etc.
The dataset described included operational
data from 2018 for normal and anomalous conditions identified by plant experts.
We proceeded by preprocessing this data to remove noise and standardizing
formats to be compatible with machine learning models.
6.2.2
Model Development: Rule induction
techniques were used to build predictive models that created interpretable
'if-else-then' rules based on historical data patterns. For instance, these
rules were tailored to detect deviations in key performance indicators like
sudden sensor readings changes and water quality parameter variations.
Ensemble learning algorithms were also
incorporated into the models to raise anomaly detection accuracy and decrease
false positives. Complex interactions between variables were analyzed using
Random Forests and Gradient Boosted Machines.
6.2.3
Model validation
Data collected in 2020 was used for
validation for the model robustness evaluation. Key metrics included:
- Accuracy:
The models' correct prediction of anomalies.
- Precision:
Fraction of predicted anomalies that are real anomalies.
- AUC
(Area Under Curve): The models'
willingness to distinguish normal from anomalous states.
The models were shown to be very
successful, especially as regular accuracies were maintained over time,
validating their applicability to real-world use cases.
6.2.4.
Predictive alerts
The new alerts were predictive; as a
result, they incorporated the anomalies into the plant's monitoring platform
(in a way that gave early warnings for anomalies). The alerts were calibrated
to strike an appropriate balance between sensitivity (detecting diseased hours)
and specificity (avoiding false alarms), which became the most important
aspect. Based on these alerts, the maintenance team would take proactive
measures to prevent downtimes and critical failures.
6.3.
Results
The introduction of AI-based maintenance
strategies in the WFI plant resulted in several significant outcomes:
- Extended
maintenance intervals: Without
unexpected failures, the plant successfully increased the interval (time)
between maintenance activities from 1 year to 18 months.
- Reduction
in downtime: Timely interventions were enabled
by the predictive alerts and this resulted in unplanned downtime being reduced
by only 30%.
- Cost
savings: The plant optimized the
maintenance schedules and estimated a 20% savings in the money spent.
- Improved
compliance: By monitoring and identifying
anomalies consistently, the plant met very stringent pharmaceutical water
quality standards with consistency.
Table
8: Performance
Metrics of Predictive Maintenance Models.
|
Metric |
Value |
|
Accuracy |
94.8% |
|
Precision |
93.5% |
|
Recall |
95.2% |
|
AUC
(Area Under Curve) |
0.96 |

Figure
4: Graphical Representation
of performance metrics of predictive maintenance models
6.4.
Key insights
That case study points to the potential to
transform the way machine learning can be used in pharmaceutical manufacturing
maintenance practices. Key takeaways include:
- Data-driven
decision-making: Once historical data is analyzed
with advanced algorithms, you can glean actionable insights otherwise hidden by
traditional methods.
- Enhanced
reliability: The predictive system did more
than its part in reducing downtime and, in general, improving the plant's total
reliability factor.
- Scalability:
This case demonstrates the scalability of AI-based solutions and shows that the
methodology presented here can be applied to other critical manufacturing
systems.
6.5.
Conclusion
Implementing predictive machine learning
models in the WFI plant provides a smooth transition from traditional
preventive maintenance to a proactive, data-based approach. The plant was able
to predict anomalies early and achieved significant cost savings, process
efficiency and compliance with pharmaceutical standards. This case study can be
an inspiration for harnessing the broader potential of AI in transforming
maintenance practice throughout the pharmaceutical industry.
7.
Challenges and Limitations
Though a great deal was achieved in
integrating predictive machine learning models to detect calibration failure in
pharmaceutical manufacturing, a number of challenges and limitations emerged
during both the development and implementation processes. These challenges show
which areas still require further development to bring more AI-based solutions
into practice in this industry. The path to fully realizing the promise of
predictive maintenance models is not free of data-related issues or regulatory
hurdles and the road is full of complex obstacles.
7.1.
Data-related challenges
However, it is one of the most challenging
problems when Machine Learning models for calibration failure detection are to
be developed due to the lack of sufficient, high-quality data. Since
calibration data from pharmaceutical manufacturing processes is seldom complete
with any missing values, is not correctly formatted and contains insufficient
historical data, there are various issues with calibration data. Premature
termination often occurs due to missing values in critical sensor readings or
environmental factors and the data formatting of sensors and instruments across
the sensors is inconsistent, which requires extensive preprocessing. In
addition, the lack of adequate historical failure data and consequently, the
lack of reliable models, is often a consequence of a lack of historical failure
data, especially given the rarity of calibration anomalies. Such data
deficiencies cause the model to underperform and may hinder the training.
A second data-related challenge is the
imbalance of calibration failures compared to successful calibrations. The
calibration failures are relatively rare and the dataset is highly skewed toward
successes. This creates a bias in the model, making it more likely to predict that
calibration will succeed and less sensitive to rare, critical failures. Techniques
such as oversampling, under-sampling or cost-sensitive learning are needed to
address this issue, making modeling from biological observations more challenging.
7.2.
Model development and performance challenges
Despite the high accuracy of machine
learning models, especially ensemble methods and neural networks, in detecting
calibration failures, dealing with model development issues is a lot of challenging.
Machine learning model interpretability is its primary concern. Finally,
advanced models, including deep learning networks, often work as black boxes where
we cannot operate in decision-making. This, in turn, offers challenges for
regulatory environments where well-formulated justification of model decisions
is necessary. The pharmaceutical industry operates in such a stringent
validation mode for automated systems that some of the opaque nature of machine
learning algorithms may not be accepted.
Also, machine learning models generalize
from type of instrument to type of instrument, which remains a problem.
Instrument calibration requirements and operational conditions vary widely and
models trained on one set of instruments may not generalize so well to another.
Unfortunately, this means models that don't perform well with all equipment
types require additional time and resources for retraining or fine-tuning to be
sure they produce reliable results. This challenge identifies the necessity of
models that can manage the variability of the instruments used in
pharmaceutical manufacturing processes.
7.3.
Implementation challenges
Several practical challenges arise in implementing
predictive maintenance models in real-world manufacturing environments.
Integration with existing systems is one of the key obstacles. Manufacturing
Execution System (MES) and Quality Management System (QMS) for Pharmaceutical
manufacturing facilities commonly use legacy systems. Advanced AI models must
be integrated into these established frameworks with great customization, which
would also require heavy technical expertise. In case of compatibility
problems, data exchange or direct demand for real-time data processing, such a
process may be slow.
Moreover, there is high resistance to adoption from personnel. Typically, operators and maintenance teams are familiar with traditional maintenance approaches, e.g. time or condition-based maintenance. Often, few can be persuaded to move away from well-established practices and use AI predictive models. To win the trust of stakeholders, it is essential to demonstrate to them that the model's accuracy is strong while the model is reliable. Key to overcoming this resistance and the smooth use of AI solutions are effective training programs, pilot tests and good communication of the benefits of predictive maintenance.
7.4
Regulatory and compliance limitations
The pharmaceutical industry sits within a
highly regulated space. It introduces compliance challenges as one moves
towards integrating machine learning models to perform critical tasks, such as
calibration failure detection. Any new technology seeks regulatory approval, which
means that extensive validation procedures are rigorously performed and
documented to prove the technology's accuracy, reliability and reproducibility.
Since pharmaceutical companies must provide deep reports explaining the
accuracy and validity of their AI-driven solutions, meeting these regulatory
requirements can greatly delay the deployment of machine learning models.
Data privacy and security, as well as
validation, are also crucial. Handling sensitive data in the manufacturing
process is even more complex and must comply with regulations like GDPR. For
companies deploying predictive maintenance models, data security is a must;
data has to be stored, processed and protected from breaches. If manufacturers
want to use AI solutions, they must strictly comply with privacy regulations,
giving them one more layer of scrutiny.
7.5.
Computational and resource constraints
An important computational resource
requirement is developing, training and deploying machine learning models for
calibration failure detection. In particular, training complex models like Deep
Neural Networks requires very high computational. These models require high-performance
hardware, i.e. GPUs and server infrastructures. Implementing and maintaining
these AI solutions is easy and pharmaceutical companies can afford access to
such advanced computational resources, but smaller pharmaceutical manufacturers
that do not have the resources at hand find it hard to do so. For this reason,
small businesses can be held back from investing in the necessary hardware
infrastructure, thus representing a significant financial constraint.
Secondly, keeping predictive systems up to
date is also storage I/O intensive. These models are deployed and need to be
monitored and retrained after deployment to adapt to changes in manufacturing
processes, sensor configurations or environmental conditions. The underlying
processes may evolve, making predictive models outdated and requiring constant
updating to stay current. The ongoing costs of model retention can be a costly
challenge for small organizations that lack devoted AI labor or infrastructure.
8.
Conclusion
Calibration failure detection based on
predictive machine learning models in pharmaceutical manufacturing is a
transformative means to reduce the time to failure and to enhance the
application of compliance with industry standards. Manufacturers can bridge the
gap between reactive vs. proactive maintenance practices by incorporating novel
algorithms like Random Forests, Support Vector Machines and Neural Networks.
The result of this shift is not only shortened downtime but also increased
accuracy and reliability, contributing to calibrations’ enabling product
quality and addressing regulatory adherence. This work presents tangible
benefits of such AI-driven approaches in case studies and experimental results
on maintenance scheduling, fault prediction and overall system performance.
Once again, these are not entirely unlike
any other advanced technological adoption; however, as is often the case,
deploying machine learning models into pharmaceutical environments presents a
few challenges. Potential solutions face the problem that these issues related
to data quality, model interpretability, combining with legacy systems and
regulatory compliance must be solved first. Furthermore, training and
maintenance of training predictive models can also be computationally costly,
which could be a bottleneck for smaller manufacturers who usually lack the
necessary infrastructure. Much work remains to be accomplished to refine these
systems to allow for their long-term success and adaptability.
We continue to see advances in AI, data
analytics and sensor technologies, which have the promise of predictive machine
learning models becoming the future of pharmaceutical manufacturing. As more
and more companies adopt these models, we can expect to see even greater
improvements in calibration accuracy, predictive maintenance and overall
production efficiency. If the pharmaceutical industry continues to innovate and
address existing challenges, we can unlock the full potential of AI-driven
solutions to create new standards for operational excellence.
Finally, predictive machine learning
models are well-positioned to revolutionize pharmaceutical manufacturing
calibration failure detection. With the help of AI, manufacturers can achieve
better operational efficiency, save money and get ready to pass stringent
industry regulations. Although much work lies ahead, these technologies are
still at the forefront of developing the industry, with enormous potential for
the future of these production processes to become smarter and more efficient.
9.
References
- Zeberli
A, Badr S, Siegmund C, Mattern M, Sugiyama H. Data-driven anomaly detection and
diagnostics for changeover processes in biopharmaceutical drug product
manufacturing. Chemical Engineering Research and Design, 2021;167: 53-62.
- Çınar
ZM, Abdussalam Nuhu A, Zeeshan Q, Korhan O, Asmael M, Safaei B. Machine
learning in predictive maintenance towards sustainable smart manufacturing in
industry 4.0. Sustainability, 2020;12: 8211.
- Carvalho TP, Soares FA, Vita R, Francisco RDP, Basto JP,
Alcalá SG. A systematic literature review of machine
learning methods applied to predictive maintenance. Computers & Industrial
Engineering, 2019;137: 106024.
- Susto
GA, Schirru A, Pampuri S, McLoone S, Beghi A. Machine learning for predictive
maintenance: A multiple classifier approach. IEEE transactions on industrial
informatics, 2014;11: 812-820.
- https://www.china-gauges.com/news/Optimizing-Measurement-Instrument-Calibration-with-Machine-Learning-Algorithms.html
- Paolanti
M, Romeo L, Felicetti A, Mancini A, Frontoni E, Loncarski J. Machine learning
approach for predictive maintenance in industry 4.0. In 2018 14th IEEE/ASME
International Conference on Mechatronic and Embedded Systems and Applications
(MESA), 2018;1-6.
- Florian
E, Sgarbossa F, Zennaro I. Machine learning-based predictive maintenance: A
cost-oriented model for implementation. International Journal of Production
Economics, 2021;236: 108114.
- Zhang
Y, Wijeratne LO, Talebi S, Lary DJ. Machine learning for light sensor
calibration. Sensors, 2021;21: 6259.
- Atamturktur
S, Hemez F, Williams B, Tome C, Unal C. A forecasting metric for predictive
modeling. Computers and Structures, 2011;89: 2377-2387.
- Sun
H, Depraetere K, Meesseman L, et al. Machine learning-based prediction models
for different clinical risks in different hospitals: evaluation of live
performance. Journal of Medical Internet Research, 2022;24: e34295.
- Sampedro
GAR, Rachmawati SM, Kim DS, Lee JM. Exploring machine learning-based fault
monitoring for polymer-based additive manufacturing: Challenges and
opportunities. Sensors,2022;22: 9446.
- Mustapää
T, Nummiluikki J, Viitala R. Digitalization of Calibration Data Management in
Pharmaceutical Industry Using a Multitenant Platform. Applied Sciences, 2022;12:
7531.
- https://ispe.org/pharmaceutical-engineering/january-february-2022/case-study-water-injection-plant-ai-based
- Golriz
Khatami S, Mubeen S, Bharadhwaj VS, Kodamullil AT, Hofmann-Apitius M,
Domingo-Fernández D. Using predictive machine learning models for drug response
simulation by calibrating patient-specific pathway signatures. NPJ systems
biology and applications, 2021;7: 40.
- Kimaina
A, Dick J, DeLong A, Chrysanthopoulou SA, Kantor R, Hogan JW. Comparison of
machine learning methods for predicting viral failure: a case study using
electronic health record data. Statistical Communications in Infectious
Diseases, 2020;12: 20190017.
- Guerra
AC, Glassey J. Machine learning in biopharmaceutical manufacturing. European
pharmaceutical review, 2018;23: 62-65.
- Gupta A, Giridhar A,
Venkatasubramanian V, Reklaitis GV. Intelligent alarm management applied to
continuous pharmaceutical tablet manufacturing: an integrated approach.
Industrial & Engineering Chemistry Research, 2013;52: 12357-12368.
- Chen
JH, Asch SM. Machine learning and prediction in medicine-beyond the peak of
inflated expectations. The New England journal of medicine, 2017;376: 2507.
- Dengler
S, Lahriri S, Trunzer E, Vogel-Heuser B. Applied machine learning for a zero
defect tolerance system in the automated assembly of pharmaceutical devices.
Decision Support Systems, 2021;146: 113540.
- Su Q, Moreno M, Ganesh S, Reklaitis GV, Nagy ZK. Resilience and risk analysis of fault-tolerant process control design in continuous pharmaceutical manufacturing. Journal of loss prevention in the process industries, 2018;55: 411-422.