Research Article
The Evolution of Large Language Models in Natural Language Understanding
1. Abstract
The realm of natural language
processing (NLP) has witnessed a significant transformation with the emergence
and evolution of Large
Language Models (LLMs). This paper provides a
comprehensive overview of the journey
from the early days of rule-based systems
and statistical models to the current era of advanced LLMs, like the Generative
Pre-trained Transformer (GPT) series. The advent of deep learning
and the introduction of architectures such as transformers have
been pivotal in this evolution, marking a shift from traditional models to more complex and effective solutions
for understanding and generating human language. Key developments in these models'
natural language understanding (NLU) capabilities have
redefined the benchmarks in various
NLP tasks, including but not limited to language translation, question
answering, and text summarization. Introducing self-attention mechanisms and bidirectional training
approaches, as exemplified in models
like BERT and GPT-3, has led to remarkable improvements
in the models' ability to grasp context, nuances, and complexities of human language.
This paper highlights the significance of these
advancements in the context of technological progress
and their broader
implications across various
sectors. While celebrating these achievements, the paper also delves into the challenges and limitations of current LLMs, such as dealing with ambiguities,
inherent biases, and ethical considerations.
The culmination of this study offers insights into the potential future directions of LLMs in NLU, underlining their growing impact on both the field of artificial intelligence
and the fabric of society.
2. Keywords: Large Language Models, Generative Pre-trained Transformer, Bidirectional
Encoder Representations from Transformers, Transformer, Natural Language
Processing
3. Introduction
In the constantly
evolving domain of Artificial Intelligence (AI), Large Language Models (LLMs)
have emerged as a cornerstone in
understanding and generating human language.
This paper introduces LLMs as advanced
AI tools that process,
interpret, and produce human language, paving the way for significant breakthroughs in Natural
Language Processing (NLP). LLMs like the Generative Pre-trained Transformer (GPT) series and Bidirectional Encoder
Representations from Transformers (BERT) represent the pinnacle
of current NLP technology, leveraging vast amounts of data and sophisticated neural network architectures to achieve an unprecedented understanding of language. The
importance of natural language understanding (NLU) within AI cannot be overstated. It is the foundation upon which machines
interpret, contextualize, and respond to human
language. NLU enables AI systems to comprehend text and speech in a meaningful and useful way for various
applications, ranging from
automated customer service and content
creation to more complex tasks like sentiment analysis and real-time translation. The evolution of NLU through
LLMs has enhanced machine interaction with humans
and transformed how we access and
process the vast expanses of information available
in natural language.
This paper aims
to provide a detailed exploration of the journey
and advancements of LLMs in NLU. It discusses the initial challenges, the groundbreaking developments, and the current
state-of-the-art in LLMs, highlighting how these models have progressively improved in understanding the subtleties and
complexities of human language. The objective
is to offer a comprehensive understanding of the evolution of LLMs, scrutinize their current
capabilities and limitations, and speculate
on their future trajectory in AI. The relevance of this paper lies in its attempt to encapsulate the rapid
advancements in LLMs, providing
insights not only to AI researchers and practitioners but also to those interested in the broader
implications of these technologies on society and various industry
sectors.
4. The
Genesis of Language Models
The evolution
of language models in natural
language processing (NLP)
traces its roots back to the era of rule-based
systems. It gradually transitions into the realm of statistical models. This progression underscores a
significant shift in the approach to
machine understanding and processing of human
language.
Initially, language
modeling was predominantly governed by rule-based systems. These systems,
developed in the mid-20th century,
relied heavily on handcrafted linguistic rules. Early examples include ELIZA and SHRDLU, demonstrating basic conversational capabilities and simple instruction understanding. However, the primary
challenge with these rule-based models was their lack of scalability and adaptability.
They were constrained by the specific rules they were programmed with, limiting their ability to handle the complexities and variations inherent
in natural language.
As the
limitations of rule-based systems became apparent, the late 1980s
and 1990s saw a paradigm
shift towards statistical models.
These models marked the inception
of machine learning approaches
in NLP, where the focus shifted from
hard-coded rules to learning from data. Statistical models such as n-gram models and Hidden Markov
Models (HMMs) emerged, capable of
learning language patterns from extensive text corpora.
This approach brought
about significant improvements in various NLP tasks like
speech recognition and machine
translation, offering a level of flexibility and power unattainable with rule-based systems (Figure 1).
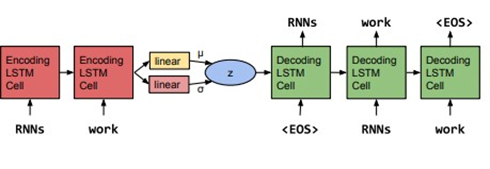
Figure 1: The core
structure of our variational auto encoder language
model. Words are represented using a learned
dictionary of embedding
vectors1.
However, these
early forays into statistical modeling were not without
their challenges. One of the most formidable hurdles was human language's inherent
ambiguity and intricacy. Early models struggled with
understanding words with multiple
meanings and the nuances of sarcasm, idioms,
and contextual implications. Additionally, there was a growing
demand for substantial computational resources and diverse, expansive datasets to train more complex
models. This need presented challenges in developing models that could effectively
generalize across different languages and contexts. Another persistent issue was the lack of standardized datasets and evaluation metrics,
which hampered the ability to compare
and benchmark the performance of various models effectively1.
This initial
phase in the development of language models laid the groundwork for future advancements in NLP. It illuminated the potential and challenges of computational language processing and set the stage for
the advent of deep learning-based models.
These new models,
powered by large-scale data, would soon address many
of the limitations faced by their
predecessors, propelling the field of NLP into a new era of innovation and discovery.
5.
The Rise of Deep Learning in NLP
The landscape
of natural language
processing (NLP) underwent a profound transformation with
the introduction of neural networks
and deep learning in language modeling. This
period significantly departed
from traditional models,
heralding a new era of advanced neural network architectures and groundbreaking innovations.
With their ability to learn complex
patterns from data, Neural networks
started replacing the earlier statistical models in NLP tasks. The growing availability of large datasets
and advancements in computational
power drove this shift. Neural networks, especially deep learning models with multiple
layers, demonstrated an unprecedented capability in capturing the subtleties of language, paving the way for more sophisticated and accurate language
processing.
One of the key breakthroughs in this era was the development of word embeddings, a technique that transformed
words into numerical vectors. Word embeddings
allowed for the representation of words in a continuous vector space, capturing semantic and syntactic
similarities between words. Word2Vec,
developed by a team at Google, was one of the
pioneering models in this space. It provided a way to train word embeddings using large text corpora,
resulting in vectors that
encapsulated meaningful linguistic relationships, such as analogies
and contextual similarities2.
Another significant advancement was the advent of recurrent neural networks (RNNs),
which are particularly suited for handling
sequential data like text. RNNs were revolutionary in their ability to process
sequences of varying lengths,
remembering information from previous elements in the sequence to inform the processing of current and future elements. This characteristic made RNNs
highly effective for language modeling
and machine translation tasks. Later developments, like Long Short-Term Memory (LSTM) networks,
addressed the challenges of training traditional RNNs, especially the issue of long-term dependencies in sequences.
The combination
of word embeddings and RNNs, along with other deep learning
architectures like Convolutional Neural Networks (CNNs),
significantly advanced the state-of-the-art in NLP. These models excelled
in various tasks, ranging from sentiment
analysis and text classification to more complex applications like speech recognition and conversational agents.
The rise of deep
learning in NLP marked a paradigm shift from rule-based and statistical models to more fluid and dynamic neural architectures. This transition enhanced the performance of NLP systems and opened up new possibilities for language understanding and generation.
The deep learning era in NLP laid the foundational structures for the sophisticated
language models that followed, setting the stage for further innovations in the field.
6. The Advent of Transformer Models
The landscape
of natural language
processing (NLP) witnessed
a groundbreaking shift with the advent of the transformer architecture, introduced by
Vaswani et al. in their 2017 paper "Attention Is All You Need." This innovative architecture departed from the then-dominant recurrent neural network (RNN) models, ushering in a new
era of language processing capabilities. The transformer model
diverged from the traditional path of sequential
data processing inherent in RNNs and LSTMs and
introduced a novel approach that allowed for the parallel
processing of sequences. This was a significant development, as it sped up the training process and
improved the model's ability to
manage long-range dependencies in text. The ability to process all sequence parts simultaneously enabled
the transformer to capture contextual relationships more efficiently and comprehensively.
At the heart of
the transformer's success is the self-attention mechanism. This mechanism allows the model to weigh and contextualize the importance of different words within a sentence, regardless of their positional distance. Unlike previous models that processed text
linearly, the self-attention mechanism
in transformers enables each word in a sentence to relate directly to every other word3. This feature enhances the model's understanding of context and linguistic nuances, allowing
for a much richer text interpretation. The self-attention
mechanism's impact on NLP has been profound,
leading to notable improvements in various tasks, including language
translation, text summarization, and question-answering,
especially in scenarios involving lengthy texts where understanding contextual relationships is crucial.
Following the transformer architecture, BERT (Bidirectional Encoder
Representations from Transformers) was introduced by Google researchers in 2018. BERT built upon the transformer model's foundational principles but introduced the bidirectional training
concept. Unlike its predecessors,
which processed text in a unidirectional manner (either left-to-right
or right-to-left), BERT analyzed text in both directions simultaneously. This bidirectional approach enabled the model to understand the
context of a word based on its entire
surrounding text, leading to a more nuanced and comprehensive understanding of language.
BERT's approach
revolutionized several NLP tasks. BERT demonstrated
exceptional performance in sentiment analysis,
named entity recognition, and question answering, where the context plays a pivotal role4. Its ability to understand the subtleties of language more holistically
set new benchmarks in the field. The model achieved this by pre-training on an extensive corpus of text, capturing a wide
array of language patterns and
structures, and then fine-tuning for specific tasks. This methodology propelled BERT to the forefront, achieving state-of-the-art results on various
NLP benchmarks.
The introduction of transformer models,
particularly exemplified by
BERT, represents a significant stride in the
evolution of NLP. These models enhanced the efficiency and accuracy
of language processing tasks and opened new frontiers
in research and applications within AI. The transformer's impact extends beyond mere performance metrics; it has fundamentally altered
how machines understand and interact with human language, paving the way for
more advanced and nuanced AI-driven
linguistic applications.
7. The Era of GPT and Large-Scale Models
The Generative Pre-trained Transformer (GPT) series by Open sAI
marked a revolutionary phase in the field of natural language processing (NLP), bringing forth an era
characterized by large-scale language models. This period was defined
by significant leaps in model complexity and the magnitude of training data,
fundamentally changing the landscape of NLP (Figure 2).

Figure 2: The five key properties of a foundation model: expressivity- to flexibly capture and represent rich information; scalability-to efficiently consume large quantities of data; multimodality-to connect various modalities and domains; memory capacity-to store the vast amount of accumulated knowledge; and compositionality-to generalize to new contexts, tasks, and environments5.
The journey began with introducing the original GPT model, a transformative step in NLP built upon the transformer architecture. This model set the stage for advanced applications in text generation, offering capabilities ranging from text completion to creative writing and translation. However, it was just the beginning of a much larger evolution.
The progression from GPT to its subsequent iterations, GPT-2 and the groundbreaking GPT-3, was marked by exponential growth in sophistication. GPT-3, in particular, stood out as a colossal model with 175 billion parameters, trained
on an extensive dataset encompassing a vast expanse
of the internet. This model represented an increase in size and a significant enhancement in language understanding and generation
capabilities. The architectural foundation remained rooted in the transformer model, but the scale of GPT-3 allowed
for unprecedented linguistic comprehension and versatility6.
When comparing
the performance of the GPT series in NLU tasks, each new version
demonstrated remarkable improvements
over its predecessors. The original GPT, while
innovative, had limitations in handling complex
language nuances and maintaining context in longer text sequences. GPT-2 made strides in addressing these
challenges, offering more coherent
and contextually accurate
text generation. However, GPT-3 broke new ground,
exhibiting proficiency in a wide range of previously unattainable tasks2. From writing creative
fiction to generating technical content, answering questions, and coding, GPT-3's
abilities stretched across a spectrum of applications, often producing results
indistinguishable from human-generated text.
In NLU tasks,
GPT-3's capacity to grasp subtleties, context,
and even implied meanings set a new benchmark. This was a substantial advancement from earlier
iterations, which, despite their
capabilities, often struggled with the deeper aspects of language comprehension.
The GPT era has
made remarkable progress, pushing the frontiers
of language understanding and generation. It has not only expanded the realm of possibilities in AI but also brought to the forefront
critical discussions about the ethical
implications, potential biases, and the broader impact of such powerful
AI tools on society and various industries.
8.
Breakthroughs and Milestones in NLU
The Natural Language Understanding (NLU) field has experienced a series of groundbreaking developments, particularly with advanced
machine learning techniques and Large Language
Models (LLMs). These breakthroughs have significantly enhanced
the ability of machines to
understand, interpret, and generate human
language with remarkable accuracy (Figure 3).

Figure 3: During
adaptation, a foundation model is converted into an adapted model (bottom row) to reflect
updated information, desired
behaviors, or deployment constraints5.
One of the most notable achievements in NLU is in language translation. Earlier machine
translation systems often produced literal
translations that lacked contextual understanding, leading to awkward
or incorrect translations. The introduction of neural machine translation (NMT), particularly
with models like Google's BERT (Bidirectional
Encoder Representations from Transformers) and Open AI's GPT-3, marked a paradigm shift. These
models utilize deep learning and
contextual understanding, enabling them to grasp the subtleties and nuances of different languages. They can now handle idiomatic
expressions, slang, and cultural references more effectively, providing
accurate, contextually relevant, and fluent translations7.
Question-answering systems
have also seen significant improvements. Early versions struggled
with anything beyond simple, fact-based queries. With the integration of LLMs, these systems can now understand and
respond to complex questions, often with nuanced
and detailed answers. They achieve this by processing and synthesizing information from extensive databases and text corpora,
effectively 'reading' and 'comprehending' vast amounts of data to provide accurate
responses. This capability is particularly evident in models trained on specific domains, such as
medical or legal texts, where they
can provide expert-level responses to queries in these fields.
Text summarization, the task of creating concise
and coherent summaries of
longer texts, has also benefitted from the
advancements in NLU. Earlier attempts at summarization often resulted in disjointed and incoherent summaries, lacking the ability to effectively identify and
convey the key points of a text.
Modern LLMs, however, can generate summaries that maintain the essence and context of the original text, making them invaluable tools for digesting and
understanding large volumes of information quickly (Figure 4).
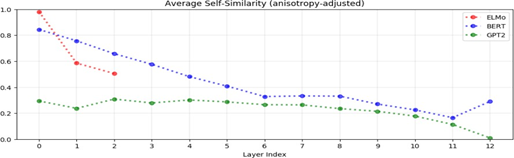
Figure 4: The average
cosine similarity between
representations of the same word in different contexts is called the word’s self-similarity.
Above, we plot the average self-similarity of uniformly randomly
sampled words after adjusting for anisotropy (see section 3.4). In all three models,
the higher the layer, the lower the self-similarity, suggesting that contextualized word representations
are more context-specific in higher layers8.
These advancements have been underscored in various NLU benchmarks and competitions, which
serve as platforms to measure and compare the capabilities of different NLP models. In benchmarks like GLUE (General
Language Understanding Evaluation) and its successor, Super GLUE, LLMs like BERT and GPT-3 have achieved remarkable results, often surpassing human performance in some tasks. These models' ability to understand
context, infer meaning, and process natural language at a high level
of sophistication is a testament to the strides
made in NLU.
In real-world applications, these advancements have profound implications. For instance, in customer service,
AI-powered chatbots can now understand and respond to customer inquiries
with high accuracy
and relevance, improving efficiency and customer
satisfaction. In the legal domain, AI systems can analyze and summarize legal
documents, assisting lawyers in their research9. Similarly,
NLU systems are used in healthcare to interpret clinical notes, aiding diagnosis and treatment planning.
Overall, the
breakthroughs and milestones in NLU mark a significant leap forward in our ability
to bridge the communication gap between humans and
machines. These advancements showcase
the technical prowess of current AI systems and open up new avenues
for innovation and application across various sectors,
fundamentally changing how we interact
with information and technology.
9. Challenges and Limitations
Despite these
advancements, current LLMs face significant challenges
in fully understanding natural language. One key limitation is handling ambiguities inherent in human language, where
context plays a crucial role in interpretation. Additionally, biases present in training data can be reflected
in the models' outputs, leading to
ethical concerns, particularly in sensitive applications.
From a computational perspective, developing and deploying
these models require
substantial computational resources, making them less accessible and
raising concerns about their environmental impact.
Ethical challenges also include
concerns about privacy, misuse of technology, and the potential displacement of human jobs.
10. Future
Directions and Potential
NLU and LLMs are poised for continued growth and innovation. Emerging trends include the
development of more efficient models that require
less computational power, addressing biases in training
data and model outputs, and creating multimodal models that
can process and integrate multiple forms
of data, such as text, images, and audio.
The implications
of these advancements are far-reaching, with
potential impacts across various sectors. For instance, advanced NLU can aid patient
care through automated
medical record analysis
and interaction. In education, personalized learning experiences can be created.
AI can provide more efficient, accurate, and personalized assistance in customer
service.
11. Conclusion
The evolution of
LLMs has profoundly impacted natural language
understanding. These models have not only pushed the boundaries of what machines
can comprehend and generate in terms of language but have also opened new avenues
for research and applications in AI. While significant achievements have marked the journey, it is also beset with challenges and ethical considerations that
must be navigated carefully. The future landscape
of NLU in AI appears
promising, with continual advancements expected to further enhance
the capabilities of machines in understanding and interacting with human language. As we
move forward, it is crucial to
balance innovation with responsibility, ensuring that ethical principles and a commitment to societal benefit guide the development of these powerful
tools.
12. References
- Bowman
SR, Vilnis L, Vinyals O, Dai AM, Jozefowicz
R, Bengio S. Generating Sentences from a Continuous Space. arXiv, 2016.
- Z. Dai, Yang Z, Yang Y, Catbonell J, Le VQ,
Salakhutdinov R. Transformer-XL: Attentive
language models beyond
a fixed-length context, arXiv,
2019;1.
- Jin D, Jin Z, Zhou
JT, Szolovits P. Is BERT Really Robust? A strong baseline for
natural language attack on text classification
and entailment. arXiv, 2019.
- Kim Y.
Convolutional neural networks for sentence classification. In Proceedings of the 2014 Conference EMNLP, 2014; 1746-1751.
- Chung
HW, Hou L, Longpre S, et al. Scaling Instruction-Finetuned Language Models. arXiv, 2022;1.
- Koroteev
MV. BERT: A review of applications in natural language
processing and understanding. arXiv, 2021.
- Panayotov V, Chen G, Povey D, Khudanpur S. Librispeech: An ASR corpus based on public
domain audio books.
2015 IEEE ICASSP,
2015; 5206-5210.
- Ethayarajh K. How Contextual are Contextualized Word Representations? Comparing the geometry of BERT, ELMo, and GPT-2 Embeddings. arXiv, 2019.
- Chan W, Jaitly N, Le Q, Vinyals O. Listen, attend and spell: A neural network for large vocabulary conversational speech recognition, 2016 IEEE ICASSP, 2016.